웹사이트를 활성화했으나 설정된 버킷 정책이 없을 때는 해당 버킷에 대한 공개 액세스가 가능하며 이때는 403 Forbidden 오류가 발생한다.
Access 에
bucket and objects not public 이기 때문
public으로 바꾸려면?
1. Block all public access 상자 체크를 해제
2. bucket policy 로 가서 공개 액세스를 허용하는 버킷 정책을 작성한다 .
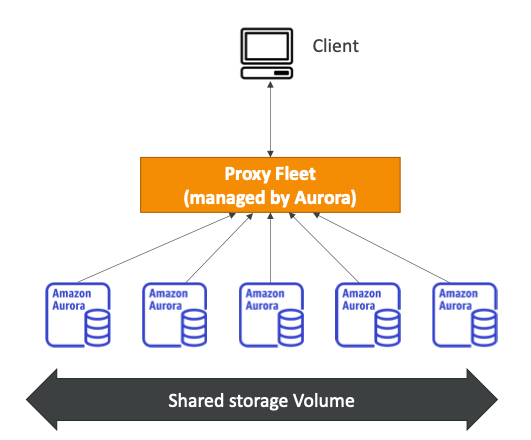
127. S3 버전 관리
Amazon S3 - Versioning
s3 파일을 버저닝 하려면 먼저 버킷 레벨에서 활성화가 되어야한다.
같은 키로 파일 버전을 다시 업로드 하는 경우에 기존 파일을 덮어쓰게 되는데 사실은 덮어쓰는게 아니라 해당 파일의 새로운 버전을 생성하는 것이다 .
same key overwrite will increment the "version" : 1,2,3
버킷을 버저닝하는 것이 최고
모든 파일 버전을 어느 정도 유지한다.
원치 않은 삭제로부터 보호
이전 버전을 복원할 수 있음 ( Easy roll back to previous version)
Notes
버저닝을 활성화하기 전에 버전 관리 되지 않은 파일은 null 버전이 된다.
버킷에서 버저닝을 중단하면 이전 버전을 삭제하는 것이 아니라 이후의 파일이 버전을 할당받지 못하도록 한다 .
Suspending versioning does not delete the previous versions
128. S3 버전 관리 실습
properties 탭에가서 버킷 버전닝을 활성화 한다.
versionID 탭이 생긴다.
활성화 전에 있던 파일의 version ID는 null 이다.
삭제시 delete marker 가 생성된다 .
129. S3 복제 노트
Amazon S3 - Replication (Notes)
복제를 활성화한 후에는 새로운 객체만 복제 대상이 된다.
기존의 객체를 복제하려면 S3 배치 복제 기능을 사용해야한다. ( S3 Batch Replication)
기존 객체 부터 복제에 실패한 객체까지 복제할 수 있는 기능이다.
삭제 마커도 복제할 수 있다.
버전 ID 로 삭제하는 경우 버전 ID는 복제되지 않는다.
체이닝 복제는 불가능함
1번 버킷이 2번 버킷에 복제 되어 있고,
2번 버킷이 3번 버킷에 복제돼 있다고 해서 1번 버킷을 객체가 3번 버킷으로 복제 되지 않는다 .
130. S3 복제 실습
1. 버킷 생성 - 버저닝 활성화 해야한다.
2. 다시 버킷 생성 - 버저닝 활서오하
오리진 버킷에서
파일업로드 하기
복제 규치 추가 하기
대상 버킷 추가하기
(대상 버킷의 소스 버킷에서 복제 활성화 이전의 객체를 복제하려면 S3 배치 작업 처리를 실행해야한다 )
새로운 파일 업로드 부터 복제 버킷에 업로드 된다 .
중요한 설정
Management 에서 복제 규칙을 선택하고 규칙 편집으로 들어가 후
삭제 마커 복제 옵션이 존재한다.
기본적으로 삭제마커는 복제 되지 않지만 이를 설정하는 기능이 있다.
삭제 마커도 복제 된다.
오리진 버킷에서 파일을 삭제해도 복제 버켓에서 파일이 삭제되지 않는다.
삭제 마커를 복제하는거지 삭제하는 행위를 복제하지 않는다 .
131. S3 스토리지 클래스
S3 스토리지 클래스
Glacier 에는
Glacier Instant Retrieval
Glacier Flexible Retruevak
Glacier Deep Archive
s3에서 객체를 생성할때 클래스를 선택할 수도 있고 수동으로 스토리지 클래스를 수정할 수도 있다.
S3 수명 주기 구성을 사용해 스토리지 클래스 간에 객체를 자동으로 이동할 수 있다.
S3 Durability and Availability
Durability:
내구성으로 만년에 한 번 객체 손실이 예상된다 .
모든 스토리지 클래스의 내구성은 같다 .
Availability:
가용성은 서비스가 얼마나 용이하게 제공되는지를 의미하며 스토리지 클래스에 따라 다르다 .
1년에 53분 동안은 서비스를 사용할 수 없다는 뜻
99.99%
S3 standard - General Purpose
99.99 가용성
빈번한 액세스
낮은 레이턴시 , 높은 처리량
두개의 기능 장애를 동시에 버틸 수 있음. ( sustain 2 concurrent facility failures)
빅데이터 분석, 모바일, 게임 어플리케이션, 콘텐츠 배포
S3 Infrequent Access
자주 액새스 하지는 않지만 필요한 경우 빠르게 액세스해야 하는 데이터
스탠다드 보다는 비용이 적다
검색 비용이 쌔다 .
One zone-IA 는 단일 az에서는 높은 내구성을 갖지만 Az 가 파괴된 경우 데이터를 잃게 된다 .
가용성은 99.5%
온프레미스 데이터를 2차 백업하거나 재생성 가능한 데이터를 저장하는데 사용된다 .
Glacier Storage Classes
콜드 스토리지
아카이빙과 백업을 위한 저비용 객체 스토리지
Glacier Instant Retrieval
밀리초 단위로 검색이 가능
분기에 한번 액세스 하는데이터
최소 보관 기간이 90일
Glacier Flexible Retrieval
Expedited 1~5min
Standard 3~5 hour
bulk 5~12 hour ,free
최소 보관 기간 90일
Glacier Deep Archive
standard 12 hour
bulk 48 hour
가장 저렴
180 일
S3 Intelligent- Tiering
사용 패턴에 따라 액세스된 티어 간에 객체를 이동할 수 있게 해준다 .
소액의 월별 모니터링 비용과 티어링 비용
frequent acces tier : default
infrequent access tier : 30days
archive instant access tier: 90 days
archive access tier : 90~700 + days 이상 액세스 하지 않은 객체에 구성
알아서 객체를 스토리지 티어간에 옮긴다.
132. S3 스토리지 클래스 실습
버킷 생성
객체 업로드 시 스토리지 클래스 추가 옵션이 나온다.
glacier 에 업로드 하기 시작하면 해당 파일은 회수하지 않는 한 볼 수 없게끔 즉시 변경된다.
파일 열람 접근을 위해서는 먼저 복원을 해야한다.
객체 스토리지 클래스를 수정할 수 있다.
Quiz 9: Amazon S3 퀴즈
1. 25GB 크기의 파일을 S3에 업로드하려 시도 중이지만, 오류가 발생하고 있습니다. 이 경우, 가능성이 있는 원인은 무엇일까요?
S3 객체 파일의 크기제한은 5TB 이다.
100mb 보다 파일이 큰 경우 멀티파트 업로드가 권장된다.
파일 크기가 100MB가 넘는 경우에는 멀티파트 업로드가 권장됩니다.
2. dev라는 이름의 새로운 S3 버킷을 생성하려 하던 중 오류가 발생했습니다. S3 버킷이 생성된 적이 없는 새로운 AWS 계정을 사용 중입니다. 이 경우, 가능성이 있는 원인은 무엇일까요?
S3 버킷 이름은 전역에서 고유해야함.
3. 이미 많은 파일을 포함하고 있는 S3 버킷에 버전 관리를 활성화한 상태입니다. 기존의 파일은 다음 중 어떤 버전을 가지고 있을까요?
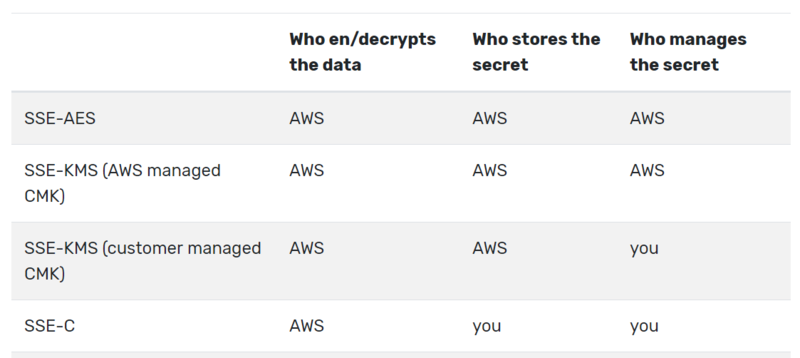
4. 여러분의 고객은 S3에 있는 파일을 암호화하되, 암호화 키를 AWS에 저장하지 않고 직접 관리하기를 원하고 있습니다. 이에 여러분은 고객에게 ............................. 를 추천했습니다.
SSE-C을 사용하면, AWS에서 암호화가 일어나지만 당사자가 암호화 키를 전적으로 관리하게 됩니다.
Server-Side Encryption
암호화 주체, 암호화 키 저장 장소, 암호화키 관리 주체
5.여러분이 근무 중인 기업이 S3에 저장된 자신들의 데이터를 암호화하고자 합니다. 암호화 키가 AWS에 저장되고 관리되더라도 문제가 없으나, 암호화 키에 대한 교체 정책은 기업이 직접 관리하기를 원하고 있습니다. 이에 여러분은 고객에게 ............................. 를 추천했습니다.
SSE-KMS를 사용하면, AWS에서 암호화가 일어나고 AWS가 암호화 키를 관리하게 되지만, 암호화 키의 교체 정책은 당사자가 전적으로 관리하게 됩니다. AWS에 저장된 암호화 키
6. 기업은 AWS의 암호화 프로세스를 신뢰하지 않으며, 애플리케이션 내에서 프로세스가 이뤄지기를 원하고 있습니다. 이에 여러분은 고객에게 ............................. 를 추천했습니다.
클라이언트 측 암호화를 사용하면, 암호화를 직접 수행해야 하며 당사자가 암호화 키를 전적으로 관리하게 됩니다. 암호화를 여러분이 직접 수행하고 암호화된 데이터를 AWS로 보냅니다. AWS는 여러분의 암호화 키에 대해 알지 못하며, 데이터를 복호화할 수 없습니다.
7. S3 버킷 정책을 업데이트해 IAM 사용자들이 S3 버킷 내의 파일을 읽기/쓰기할 수 있도록 허가했으나, 한 명의 사용자가PutObject API 호출을 수행할 수 없다며 불만을 토로하고 있습니다. 이 경우, 가능성이 있는 원인은 무엇일까요?
IAM 정책 내의 명시적인 부인(DENY)은 S3 버킷 정책보다 우선적으로 고려됩니다.
8. S3 버킷으로부터 파일을 로딩해 오는 웹사이트가 있습니다. 파일의 URL을 Chrome 브라우저에 직접 입력했을 때에는 정상적으로 작동했으나, 이 웹사이트에서 파일을 로딩하려 할 때는 작동이 되지 않습니다. 무엇이 문제일까요?
Route 53의 ttl 정책 때문에 항상 a레코드 타입을 쓸 수는 없다. alias 존재 이유
119. MyClothes.com
Stateful Web App: MyClothes.com
이번엔 Stateful 웹 앱인 myClothes.com 을 예로 들어보자.
옷을 살 수 있고, 장바구니가 있고
동시에 수백 명의 사용자가 있다.
수평 확장을 하고 싶으며 앱을 stateless로 유지하게 해야한다.
사용자는 장바구니를 잃어버리면 안된다.
또한 주소 등의 사용자 정보를 효과적으로 보관하고 어디에서나 접근할 수 있는 데이터베이스에 저장할 거다.
ASG 사용
ELB로 트래픽을 각 ASG 로 보낸다고 가정하자
A 인스턴스에서 장바구니를 만들고
다음 연결에서 B인스턴스에 연결되면 장바구니가 사라진다.
사용자가 같은 ASG 의 인스턴스에 연결되게 할려면 세션을 켜야한다.
ELB session 사용
고착도 , 세션 밀접성을 도입해야한다.
Stickiness 을 설정하면 ELB에서 특정한 인스턴스로만 접근한다.
세션을 사용해도 인스턴스가 종료되면 장바구니를 잃어버리게 된다. ㄴ
Introduce User Cookie
사용자 쿠키를 사용해보자
만약 장바구니에 대한 정보를 사용자가 지니고 있다면?
인스턴스들은 장바구니에 대한 정보를 알 필요가 없다. -> stateless 하게 된다.
사용자 , 클라이언트에서 계속 인증하니까
하지만 데이터를 전송할 때마다 사용자에 대한 정보를 보내므로 HTTP 요청이 무거워진다.
또한 전송과정에서 사용자의 쿠키가 변경되면 보안 위험도 존재한다 .
따라서 EC2 인스턴스가 사용자 쿠키 내용을 점검해야한다.
Cookie must be validated
전체 쿠키의 크기는 4kb 이하까지만 가능해 쿠키 내에는 매우 작은 정보만 저장 가능
대량의 셋은 불가하다.
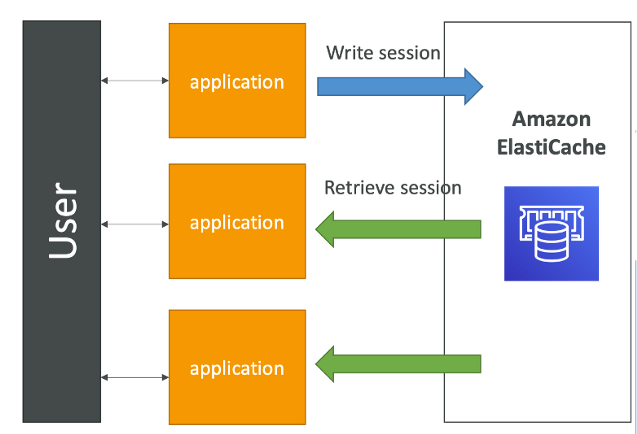
Introduce Server Session
전체 장바구를 웹 쿠키로 보내는 대신에 단순 세션 ID 만 보내는 것이다.
백그라운드에는 ElastiCache 클러스터가 존재한다.
세션 ID를 보낼 때 EC2 인스턴스에게 '이 물건을 장바구니에 추가할 거야'라고 말한다.
EC2 인스턴스는 장바구니 내용을 ElastiCache 에 추가하고 이 장바구니 내용을 불러올 수 있는 ID가 바로 세션 ID 가 된다. ( 사용자 세션 ID를 EC2 를 걸쳐 ElastiCache 에 저장하고, EC2 에 작업이 생길 때마다 ElastiCache 에서 세션 ID를 찾는다.)
ElastiCache 는 1천분의 1초 이하의 성능을 가졌다. 따라서 이 모든 것이 매우 빠르게 진해오딤 .
세션 데이터는 DynamoDB에 저장한다.
ElastiCache 내부를 수정할 수 없기 때문에 훨씬 안전하다.
Storing User Data in a database
사용자 데이터를 RDS에 저장한다.
RDS 는 인스턴스와 통신할 수 있으며 일종의 다중 AZ stateless 솔루션을 효과적으로 얻을 수 있다.
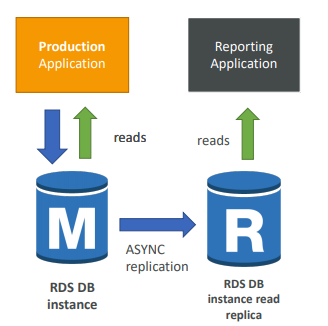
Scaling Reads
사용자가 매우 많아졌다고 가정하자.
RDS 읽기 전용 복제본을 사용한다. (최대 5개의 replicas 가능)
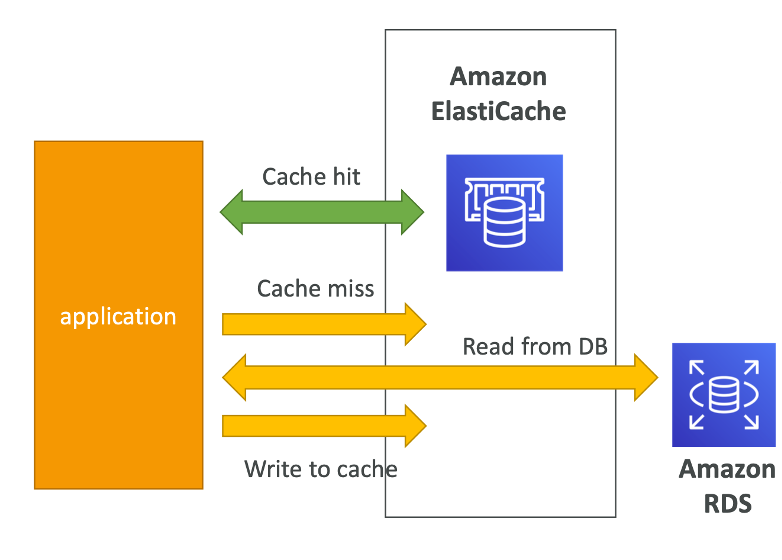
Scaling Reads (Alternative) - Write Through
EC2 인스턴스에서 데이터를 찾을때 먼저 elastiCache 를 확인한다. cache miss
데이터가 없으면 RDS 에 찾아보고 해당 데이터를 elastiCache에 캐싱한다 . cache hit 를 위해
캐싱 했기 때문에 rds 상의 트래픽을 줄이고 동시에 성능을 높일 수 있다.
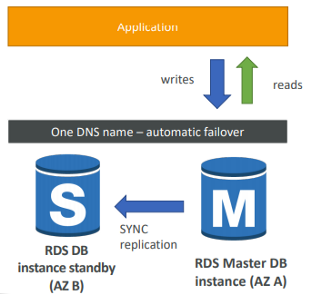
Multi AZ - Survive disasters
다중 AZ ELB가 있다.
route 53 도 가용성이 높다.
로드밸런서를 다중 AZ로 만든다 .
오토 스케일링 그룹도 다중 AZ
RDS 역시 다중 AZ
대기 복제본을 만드는 것도 방법이다.
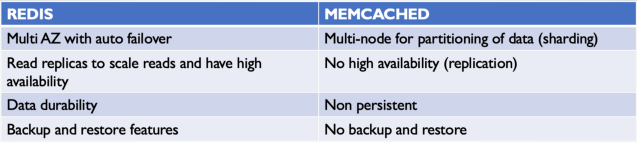
레디스를 사용한다며 ElastiCache도 다중 AZ 기능을 가짐.
철저한 보안그룹
3 tier 아키텍처를 위한 팁
클라이언트, 웹, 데이터베이스
ELB 고정 세션
웹 쿠키를 이용한 stateless 애플리케이션
ElastiCache
- 세션 저장 ( 또는 dynamodb 사용)
- RDS 캐싱
- 다중 AZ
RDS
- 사용자 데이터 저장
- 읽기 복제본 생성
- 다중 az for DR
철저한 보안그룹 설정
120. MyWordPress.com
완전히 확장 가능한 WordPress 웹 사이트 만들기
사진을 업로드하고 보여주는 기능
사용자 데이터, 콘텐츠는 mySql 에 저장된다.
확장하고 싶다면 ?
RDS를 Aurora 로 교체
다중 az, read replicas, 글로벌 데이터베이스 사용 가능
Storing images with EBS
EBS에 사진을 저장하는 경우
ELB에서 다른 두개의 인스턴스와 각각 EBS가 연결되어있다면
한쪽 EBS 만 사진을 갖는다 .
EBS 볼륨의 단점은 하나의 인스턴스만 있을 때는 잘 작동하지만 다중 AZ 또는 다중 인스턴스로 확장을 시작하면 문제가 생기기 시작한다 .
Storing images with EFS
EFS 는 네트워크 파일시스템 nfs 이다.
EFS 드라이브에 접근하기 위해 각 AZ 에 ENI 를 생성한다.
정리
Aurora Db를 이용하여 쉽게 다중 az 와 읽기 복제본을 생성한다.
EBS 에 데이터를 저장 ( 단일 애플리케이션에 유리)
Vs Storing data in EFS ( 분산 애플리케이션에 유리
EFS가 EBS 보다 비싸다.
121. 애플리케이션을 빠르게 인스턴스화 하기
Instantiating Application quickly
풀 스택을 실행하면 애플리케이션을 설치하고 데이터 삽입 및 복구하고 모든 내용을 구성한 다음
애플리케이션을 실행하는데 매우 긴 시간이 걸린다. 어떻게 하면 더 빨리 할 수 있을까?
full stack ( EC2, EBS, RDS)
클라우드의 이점을 활용하면 된다 .
EC2 Instances:
1. Golden AMI 사용
애플리케이션과 OS 종속성(dependencies) 등 모든 것을 사전에 설치하고 그것으로부터 AMI를 생성한다.
애플리케이션 ,OS 종속성 등을 재설치할 필요가 없다. 모든 것이 이미 설치된 상태에서 바로 실행된다.
2. 사용자 데이터 부트스트래핑
인스턴스가 처음 시작될 때 구성하는 것
애플리케이션, OS 종속성 등을 설치하기 위해 부트스트래핑을 할 수 있다.
매우 느리다.
3. 하이브리드
Elastic BeanStalk 은 ami를 구성하고 사용자 데이터를 추가하는 방식
RDS Databases:
스냅샷으로부터 복구
EBS Volumes:
스냅샷으로부터 복구
122. Beanstalk 개요
Developer problems on AWS
인프라 관리, 코드 배포, db lb 에 대한 환경 구성, 스케일링 문제등
고려해야할 문제가 많다.
개발자는 코드만 신경 쓰게 하자.
Elastic Beanstalk - Overview
여러 aws 서비스로 구성된다.
관리형 서비스
자동으로 용량 프로비저닝, 로드 밸런싱, 스케일링, 애플리케이션 상태 체크, 인스턴스 구성
코드만 신경 쓰면된다.
여전히 각각의 구성 요소를 완전히 제어할 수 있다.
beanstalk은 하나의 인터페이스에 통합되어 있음.
beanstalk 은 무료이지만 구성요소인 aws 서비스는 지불해야함.
Elastic Beanstalk - Components
Beanstalk의 구성요소는 애플리케이션으로 이루어져 있다.
(환경, 버전, 구성 등)
애플리케이션 버전
애플리케이션 코드의 반복이다. 버전1, 버전2,.... 등이 있을 수 있다
애플리케이션 환경
특정 애플리케이션 버전을 실행하는 리소스의 모음이다.
환경 내에서는 한 번에 하나의 애플리케이션 버전만 존재할 수 있다.(onlt on application version at a time)
환경 내에서 애플리케이션 버전을 버전 1에서 버전 2로 업데이트 할 수 있다.
Beanstalk에서는 서로 다른 두개의 티어를 가질 수 있다.
웹 서버 환경 티어와 작업자 환경티어
다양한 환경을 만들 수 있다. ( dev, test, prod 등)
애플리케이션을 생성하고 버전을 업로드하고 환경을 실행하고 그 후에는 환경 수명 주기를 관리한다.
이를 반복한다.
Beanstalk이 지원하는 언어
Go, Java SE, Java with Tomcat .NET Core on Linux
.NET Core on Windows Server Node.js, PHP
Python, Ruby, Packer Builder Single Container Docker
Multi-container Docker Preconfigured Docker 등입니다
지원하는 언어가 없다면 사용자 지정 플랫폼을 만들 수 있는 고급 기능이 있다.
beanstalk 에서는 거의 모든 것을 배포할 수 있다.
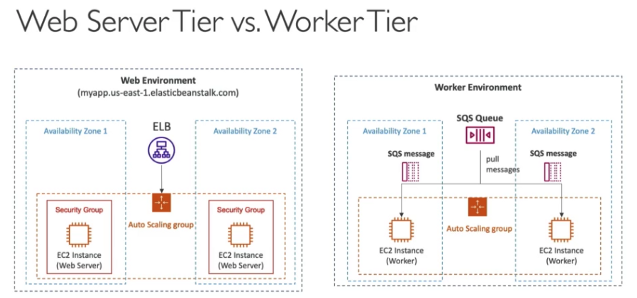
Webserver Tier vs Worker Tier
웹서버 티어와 작업wk티어는 무슨 뜻일까?
웹티어는 1번 , 전통적인 방식의 아키텍처로 로드 밸런서가 있고 웹서버가 될 다수의 EC2 인스턴스가 있는 오토 스케일링 그룹으로 트래픽을 보낸다 .
작업자 티어는 2번
여기서 클라이언트가 ec2 인스턴스에 직접 접근하지 않는다.
메시지 대기열인 sqs 대기열을 사용한다.
메시지가 sqs 대기열로 전송된다.
ec2 인스턴스들이 작업자가 된다. sqs 대기열로부터 메시지를 가져와서 처리한다.
sqs 메시지 숫자에 따라 ec2 인스턴스가 확장된다.
웹 환경이 작업자 환경의 sqs 대기열로 메시지를 푸시함으로써 웹 환경과 작업자 환경이 함께 할 수 있다. ?
1. 웹사이트 TriangleSunglasses.com는 Application Load Balancer가 관리하는 오토 스케일링 그룹에서 관리 중인 EC2 인스턴스 플릿에 호스팅되어 있습니다. ASG는 웹사이트로 들어가는 트래픽을 온디맨드 기반으로 스케일링하도록 구성되었습니다. 비용 절감을 위해, ASG가 ALB로 통하는 트래픽을 기반으로 스케일링을 하도록 구성해 둔 상태입니다. 솔루션의 고가용성을 보장하기 위해, ASG를 업데이트하고 최소 용량을 2로 설정했습니다. 요구 사항을 충족시키되, 비용을 더욱 절감하려면 어떤 작업을 해야 할까요?
어떤 상황이건 2개의 EC2 인스턴스를 실행하면 추가적인 비용을 절감할 수 있습니다.
2. 다음 중 "무상태" 애플리케이션 티어를 설계하는 데에 도움이 되지 않는 것을 고르세요.
EBS 볼륨은 특정 AZ에 저장되며, 한 번에 하나의 EC2 인스턴스에만 연결될 수 있습니다.
EBS 볼륨은 az에 생성! | 하나의 EC2 인스턴스에만 연결된다.
3. 관리 중인 Linux EC2 인스턴스 100s에 소프트웨어 업데이트를 설치하려 합니다. 이 업데이트를 EC2 인스턴스로 동적으로 로딩되어야 하며, 많은 양의 연산을 요구해서는 안 되는 공유 스토리지에 저장하고자 합니다. 어떤 방법을 사용해야 할까요?
EFS는 EC2 인스턴스의 100s에 동일한 파일 시스템을 마운트할 수 있게 해주는 네트워크 파일 시스템(NFS)입니다. EFS에 소프트웨어 업데이트를 저장하면 각 EC2 인스턴스가 이들을 평가할 수 있게 됩니다.
4. 솔루션 아키텍트로서, 여러분은 복잡한 ERP 소프트웨어 스위트를 AWS Cloud로 이전하려 합니다. 오토 스케일링 그룹이 관리하는 한 세트의 Linux EC2 인스턴스에 소프트웨어를 호스팅할 계획입니다. 소프트웨어가 Linux 기기를 준비하는 데에는 보통 한 시간 이상이 걸립니다. 스케일 아웃이 발생할 경우, 설치 과정을 빠르게 만들기 위해서는 어떤 방법을 추천할 수 있을까요?
Golden AMI는 설치되고 구성된 전체 소프트웨어를 포함한 이미지이기 때문에, 향후 이 AMI로부터 EC2 인스턴스를 빠르게 부팅할 수 있습니다.
5. 애플리케이션을 개발 중에 있으며, 최소 비용을 사용해 이 애플리케이션을 Elastic Beanstalk으로 배포하려 합니다. 이를 위해서는, 애플리케이션을 .................. 에서 실행해야 합니다.
문제에서 애플리케이션이 아직 개발 단계에 있으며 비용을 절감하고자 한다고 언급하고 있습니다. 단일 인스턴스 모드는 하나의 EC2 인스턴스와 하나의 탄력적 IP를 생성합니다.
6.애플리케이션을 Elastic Beanstalk으로 배포하던 도중, 배포 프로세스가 극도로 느리다는 것을 알게 되었습니다. 로그를 검토한 결과, 종속성이 매 배포 당 각 EC2 인스턴스로 리졸브된다는 사실을 발견했습니다. 영향을 최소화하면서 배포 프로세스를 빠르게 하려면 어떻게 해야 할까요?
Golden AMI는 전체 소프트웨어, 종속성 및 구성을 포함하는 이미지이기 때문에, 향후 이 AMI로부터 EC2 인스턴스를 빠르게 부팅할 수 있습니다.
1. 여러분은 Amazon Route 53 Registrar를 위해 mycoolcompany.com를 구매했으며, 이 도메인이 Elastic Load Balancer인 my-elb-1234567890.us-west-2.elb.amazonaws.com를 가리키게끔 하려 합니다. 이런 경우, 다음 중 어떤 Route 53 레코드 유형을 사용해야 할까요?
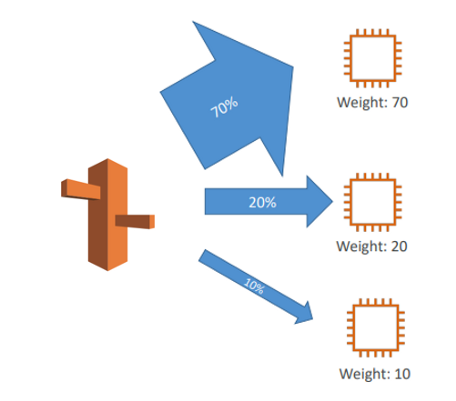
2.새로운 Elastic Beanstalk 환경을 배포한 상태에서, 5%의 프로덕션 트래픽을 이 새로운 환경으로 다이렉트하려 합니다. 이를 통해 CloudWatch 지표를 모니터링하여, 새로운 환경에 있는 버그를 제거할 수 있게 됩니다. 이런 작업을 위해서는 다음 중 어떤 Route 53 레코드 유형을 사용해야 할까요?
가중치 기반 라우팅 정책을 사용하면 가중치(예: 백분율)를 기반으로 트래픽의 일부를 리다이렉트할 수 있습니다. 트래픽의 일부를 애플리케이션의 새로운 버전으로 보내는 방식은 흔히 사용되는 방식입니다.
트래픽을 분산 시키는 것을 목적이라면 가중치 기반, 지리적 근접성을 라우팅 정책으로 한다.
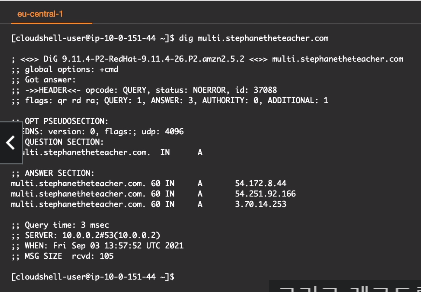
3. Route 53 레코드의 myapp.mydomain.com 값이 새로운 Elastic Load Balancer를 가리키도록 업데이트를 했는데도 불구하고, 사용자들은 여전히 기존의 ELB로 리다이렉트 되고 있는 상태입니다. 이런 경우, 가능성이 있는 원인은 무엇일까요?
각 DNS 레코드는 클라이언트들이 이러한 값들을 캐시할 기간을 지정하고 DNS 요청으로 DNS 리졸버에 과부하를 일으키지 않도록 지시하는 TTL(타임 투 리브)을 갖습니다. TTL 값은 값을 캐시해야 하는 기간과 DNS 리졸버로 들어가야 하는 요청의 수 사이의 균형을 유지할 수 있도록 설정되어야 합니다.
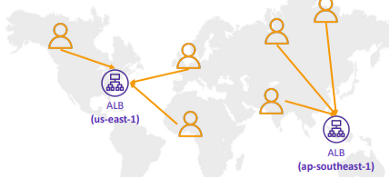
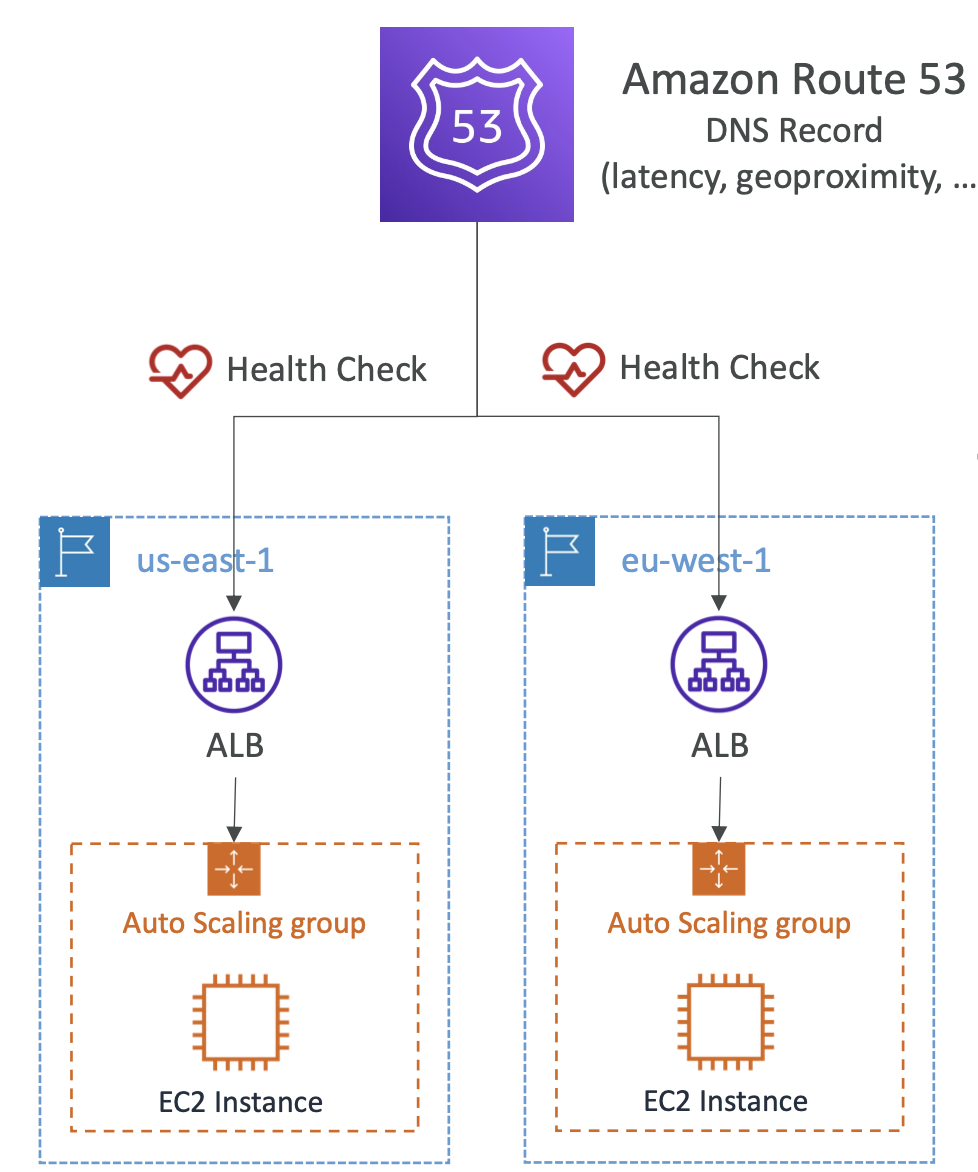
4. 두 AWS 리전,us-west-1및eu-west-2에 호스팅 된 애플리케이션이 있습니다. 애플리케이션 서버의 사용자에 대한 응답 시간을 최소화하여, 사용자들에게 최상의 사용자 경험을 제공하려 합니다. 이 경우, 다음 중 어떤 Route 53 라우팅 정책을 사용해야 할까요?
지연 시간 라우팅 정책은 사용자와 AWS 리전 사이에서 발생하는 지연 시간을 평가하여 지연 시간(예: 응답 시간)을 최소화할 수 있는 DNS 응답을 수신할 수 있게 해줍니다.
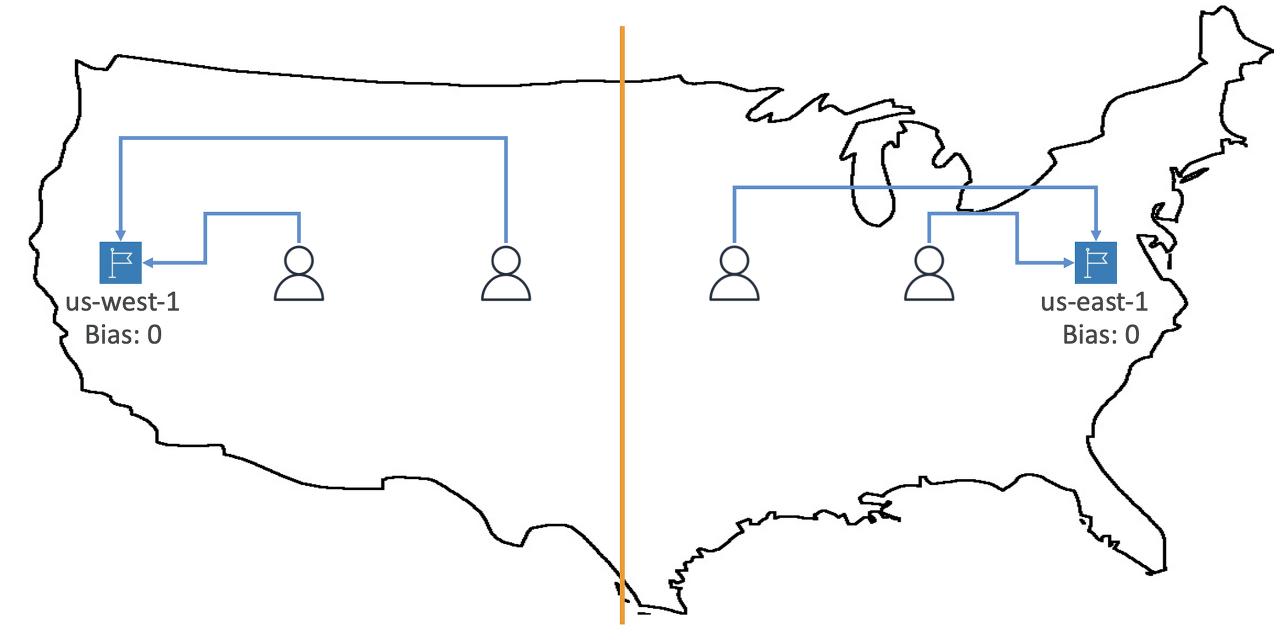
5. 프랑스를 제외한 국가에 있는 사람들이 여러분의 웹사이트로 액세스해서는 안 된다는 법적 요구 사항이 있습니다. 이 경우, 다음 중 어떤 Route 53 라우팅 정책을 사용해야 할까요?
6. GoDaddy를 위해 도메인을 구매했으며, Route 53을 DNS 서비스 제공자로 사용하려 합니다. 이를 위해서는 어떤 작업을 수행해야 할까요?
공용 호스팅 영역은 인터넷을 통해 웹사이트로 요청을 보내는 사람들이 사용할 것을 전재하고 있습니다. 마지막으로, NS 레코드는 타사 Registrar에 업데이트되어야 합니다.
2. 한 가용 영역에 재해 상황이 발생하더라도 반드시 MySQL 데이터베이스을 사용할 수 있도록 만들기 위한 새로운 솔루션을 계획하고 있습니다. 무엇을 사용해야 할까요?
다중 AZ는 전체 AZ가 차단되었을 경우의 재해 복구를 계획하는 데에 도움이 됩니다. 전체 AWS 리전이 차단될 경우에 대비해 계획을 세울 때에는, AWS 리전에 걸친 백업과 복제본을 사용해야 합니다.
3. RDS 데이터베이스가 웹사이트에서 들어오는 요청량을 처리하는 데에 어려움을 겪고 있습니다. 백만 명의 사용자들은 대부분 뉴스를 읽고 있으며, 뉴스가 자주 포스팅되는 편은 아닙니다. 이 문제를 해결하기 위해 사용해서는 안 되는 솔루션은 무엇인가요?
시험 문제를 읽을 때는 주의하시기 바랍니다. 이 문제에서는, 이런 문제점을 해결하기 위해 사용해서는 "안 되는" 솔루션이 무엇인지 묻고 있습니다. ElastiCache와 RDS 읽기 전용 복제본은 읽기 스케일링에 도움이 됩니다.
4. RDS 데이터베이스에 읽기 전용 복제본을 설정해 두었지만, 소셜 미디어 포스트를 업데이트할 시 업데이트가 바로 이루어지지 않는다는 점에 대해 사용자들이 불만을 토로하고 있습니다. 이 경우, 가능성이 있는 원인은 무엇일까요?
5.다음 RDS(Aurora 아님) 기능들 중, 사용 시 SQL 연결 문자열을 변경하지 않아도 되는 것은 무엇인가요?
다중 AZ는 활성화 상태의 데이터베이스 종류와 상관 없이 동일한 연결 문자열을 유지합니다.
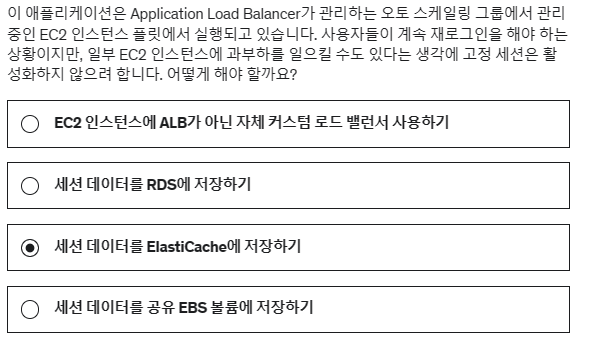
6. 이 애플리케이션은 Application Load Balancer가 관리하는 오토 스케일링 그룹에서 관리 중인 EC2 인스턴스 플릿에서 실행되고 있습니다. 사용자들이 계속 재로그인을 해야 하는 상황이지만, 일부 EC2 인스턴스에 과부하를 일으킬 수도 있다는 생각에 고정 세션은 활성화하지 않으려 합니다. 어떻게 해야 할까요?
세션 데이터를 ElastiCache에 저장하는 방법은 서로 다른 EC2 인스턴스들이 필요 시 사용자의 상태를 회수할 수 있게끔 하기 위해 흔히 사용됩니다.
7. 현재 어떤 분석 애플리케이션이 주요 프로덕션 RDS 데이터베이스에 대한 쿼리를 수행하고 있습니다. 이러한 쿼리들은 언제든 실행되어, RDS 데이터베이스의 성능을 낮추고 사용자 경험에 영향을 미치게 됩니다. 사용자 경험을 증진시키기 위해서는 어떻게 해야 할까요?
읽기 전용 복제본을 설정하면 분석 애플리케이션이 쿼리를 수행할 수는 있으나, 이 쿼리들이 주요 프로덕션 RDS 데이터베이스에는 영향을 미치지 않게 되므로 도움이 됩니다.
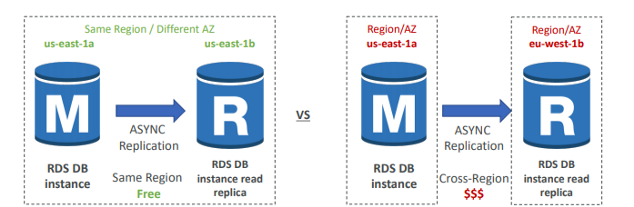
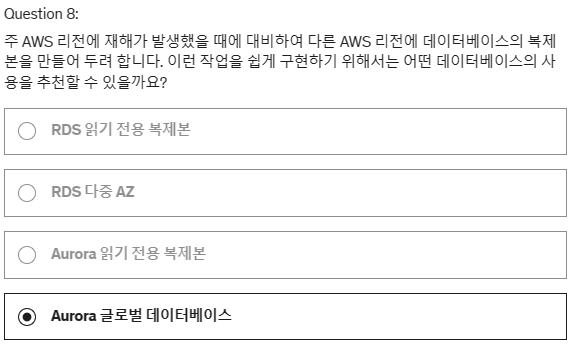
8. 주 AWS 리전에 재해가 발생했을 때에 대비하여 다른 AWS 리전에 데이터베이스의 복제본을 만들어 두려 합니다. 이런 작업을 쉽게 구현하기 위해서는 어떤 데이터베이스의 사용을 추천할 수 있을까요?
다중 AZ는 AWS 리전 수준의 재해가 발생할 경우에는 도움이 되지 않습니다. 다중 AZ는 AZ 수준의 재해 발생 시에는 도움이 됩니다.
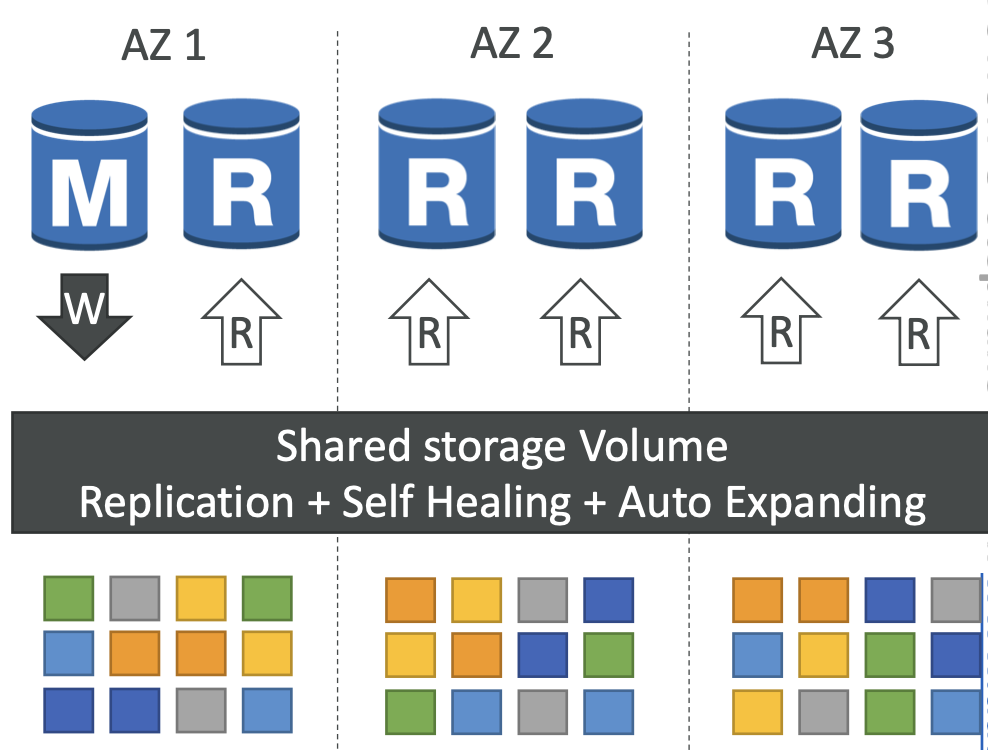
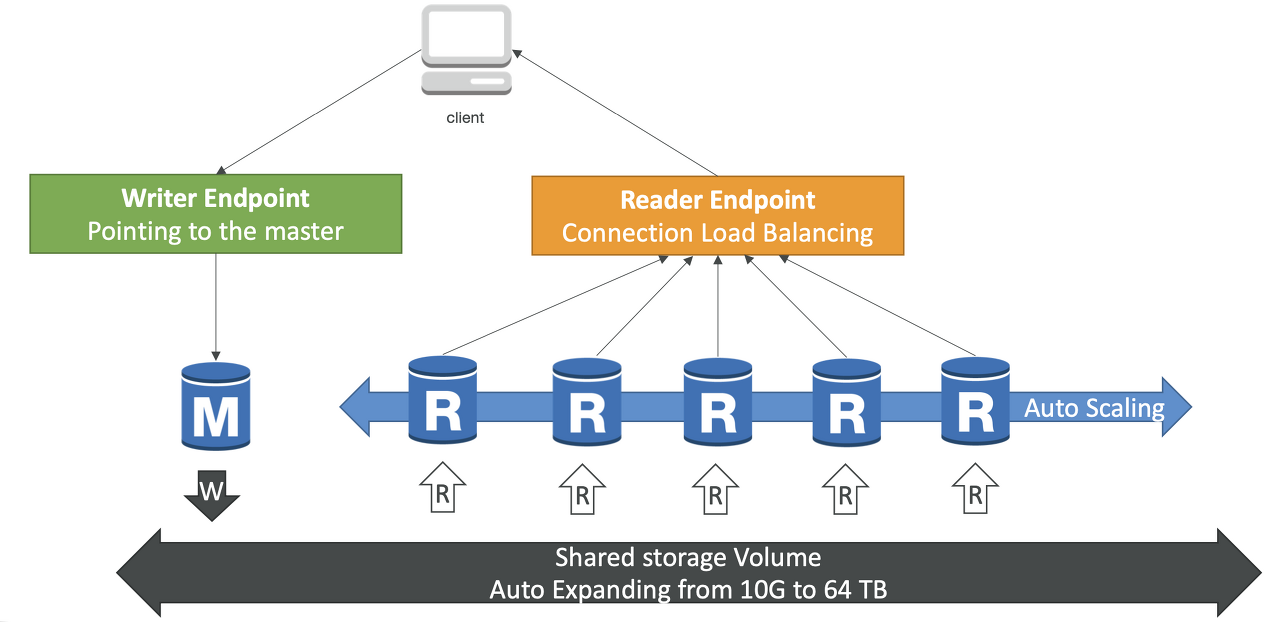
Aurora 글로벌 데이터베이스를 사용하면 최대 5개의 2차 리전까지 Aurora 복제본을 가질 수 있습니다.
9. 사용자들이 연결되었을 때, 비밀번호를 입력하도록 하여 ElastiCache Redis 클러스터의 보안을 높이기 위해서는 어떻게 해야 할까요?
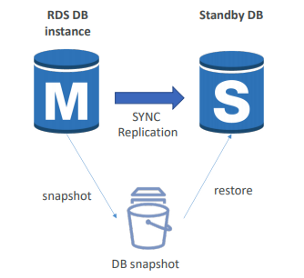
10. 리전에 정전이 발생하더라도 데이터베이스가 다른 AWS 리전에서 빠르게 워크로드 읽기와 쓰기 작업을 수행할 수 있게끔 RDS PostgreSQL 데이터베이스의 재해 복구 전략을 생성하려 합니다. DR 데이터베이스의 고가용성은 보장되어야 합니다. 어떤 방법을 추천할 수 있을까요?
11. 여러분이 근무 중인 기업은 RDS MySQL 5.6을 데이터베이스로 사용하는 프로덕션 Node.js 애플리케이션을 가지고 있습니다. Java로 프로그래밍된 새로운 애플리케이션은 정기적인 대시보드 생성을 위해 많은 양의 분석 워크로드를 수행할 예정입니다. 이 경우, 주요 애플리케이션에 발생하는 지장을 최소화하기 위해 구현할 수 있는 방법 중 가장 비용 효율적인 솔루션은 무엇인가요?
12.MySQL 데이터베이스를 온프레미스에서 RDS로 이전해 둔 상태입니다. 여러 애플리케이션과 개발자들이 이 데이터베이스와 상호작용을 하고 있습니다. 각 개발자들은 기업의 AWS 계정 내에 IAM 사용자를 가지고 있습니다. 각 개발자들을 위해 DB 사용자를 생성하는 대신, 이들에게 MySQL RDS DB 인스턴스로의 액세스를 부여하기 위해서는 어떤 접근법을 취해야 할까요?
IAM 데이터베이스 인증
13.다음 중 RDS 읽기 전용 복제본과 다중 AZ로의 복제 작업을 적절하게 묘사한 설명은 무엇인가요?
14.암호화되지 않은 RDS DB 인스턴스를 암호화하는 방법은 무엇인가요?
15. RDS 데이터베이스를 위해 최대 ............개의 읽기 전용 복제본을 가질 수 있습니다.
RDS 읽기 전용 복제본을 5개까지 가질 수 있다.
16.다음 중 IA웹 서버 M 데이터베이스 인증을 지원하지 않는 RDS 데이터베이스 기술은 무엇인가요?
17. 암호화되지 않은 RDS DB 인스턴스가 있는 상태에서 읽기 전용 복제본을 생성하려 합니다. RDS 읽기 전용 복제본이 암호화되도록 구성할 수 있을까요?
암호화되지 않은 RDS DB 인스턴스로는 암호화된 읽기 전용 복제본을 생성할 수 없습니다.
18. 프로덕션에서 실행 중인 한 애플리케이션이 Aurora 클러스터를 데이터베이스로 사용하고 있습니다. 여러분의 개발 팀은 필요할 경우 많은 양의 워크로드를 수행할 수 있는, 스케일이 축소된 애플리케이션에서 애플리케이션의 버전을 실행하려 합니다. 애플리케이션은 대부분의 시간 동안 사용되지 않습니다. CIO는 여러분에게 팀을 도와 비용을 최소화하는 동시에 이를 달성해 줄 것을 요청했습니다. 어떤 방법을 사용해야 할까요?
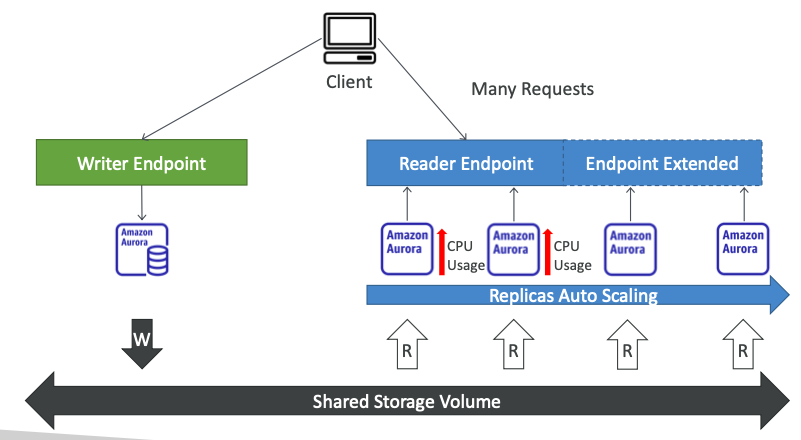
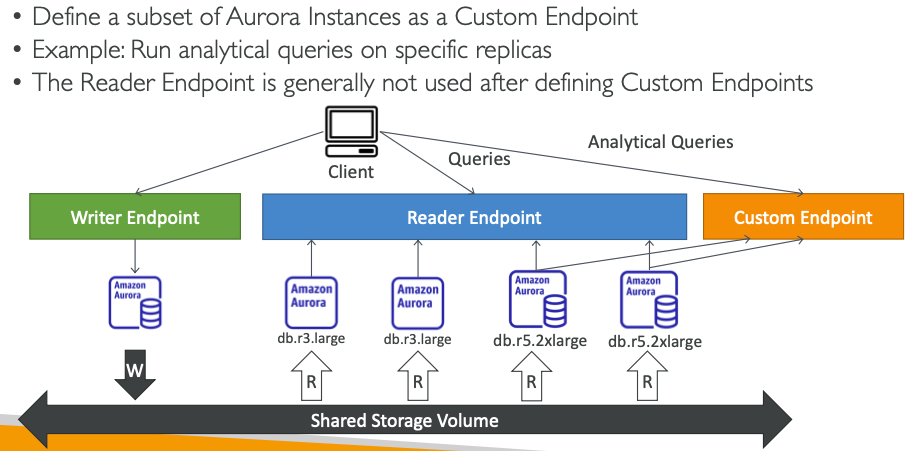
19. 하나의 Aurora DB 클러스터는 몇 개의 Aurora 읽기 전용 복제본을 가질 수 있을까요?
20. Amazon Aurora는 .......................... 데이터베이스를 모두 지원합니다.
21. 여러분은 게임 개발 업체에서 솔루션 아키텍트로 근무하고 있습니다. 하나의 게임에서, 실시간 점수를 기반으로 플레이어들의 랭킹을 매겨야 합니다. 여러분의 상사가 게임 리더보드 생성을 위해 효율적이고 고가용적인 솔루션을 설계해 구현해 줄 것을 요청했습니다. 무엇을 사용해야 할까요?
대상 그룹이 존재하기 위해서는 , 등록을 위해서는 서버의 사설 IP 가 대상 그룹에게 지정되어야한다.
-> 대상그룹 2를 쓰고 싶으면 사설 IP를 등록해야한다.
쿼리 내용을 기반으로 다른 대상 그룹을 연결 시키는 예시이다.
Application Load balancer (v2) Good to know
로드 밸런서를 사용하는 경우에도 고정 호스트 이름이 부여된다.
애플리케이션 서버는 클라이언트의 IP를 직접 보지 못한다.
클라이언트의 실제 IP는 X-Forwarded-For 라고 불리는 헤더에 삽입된다.
X-Forwarded-Port 를 사용하는 포트와 X-Forwarded-Proto 에 의해 사용되는 프로토콜을 얻는다.
즉 클라이언트의 IP인 12.34.56.78 가 로드밸런서와 직접 통신해 연결 종료라는 기능을 수행한다.
로드밸런서가 EC2 인스턴스와 통신할 때에는 사설 IP인 로드밸런서 IP를 사용해 EC2 에 들어가게 된다.
EC2 인스턴스가 클라이언트의 IP를 알기 위해서는 HTTP 요청에 있는 추가 헤더인 X-Forwarded-port, proto를 확인해야한다. (간접적으로 확인)
75. Application Load Balancer (ALB) 실습 Part 1
ALB 생성하기
HTTP, HTTPS를 고르자
1단계 : Load Balancer 구성
DemoALB
인터넷 경계
IPv4
가용 영역 선택
가용 영역당 1개의 서브넷만 지정할 수 있다.
리스너 구성
2단계는 보안 설정 구성인데
뒤에 가서 하자.
3단계 : 보안 그룹 구성
4단계: 라우팅 구성
새 대상 그룹을 만든다. my-first-target-group
상태 검사 옵션 값은 위와 같이 한다.
5단계: 대상 등록
대상 그룹에 등록할 인스턴스가 없기 때문에 생성하러 가자
인스턴스 등록
#!/bin/bash
# Use this for your user data (script from top to bottom)
# install httpd (Linux 2 version)
yum update -y
yum install -y httpd
systemctl start httpd
systemctl enable httpd
echo "<h1>Hello World from $(hostname -f)</h1>" > /var/www/html/index.html
3개 만들기 , 같은 서브넷으로 만든다.
대상 그룹에 인스턴스 2개만 추가하자.
ALB 체크하기
생성된 DNS 로 접속해보자
인스턴스 의 보안그룹은 22port 만 열려있다. 사용자 데이터 스크립트는 잘 실행되었다.
계속 타임 아웃이 뜨길래 보안그룹 문제라고 생각했다.
alb의 보안그룹은 80번 포트로 모든 소스에 열려있다.
인스턴스의 보안그룹은 22번 포트로 모든 소스에 열려있다.
alb에서 인스턴스로 들어갈려면 80번 포트를 열고 alb의 sg를 소스로 하는 인바운드 규칙을 추가한다.
launch-wizard 의 보안 그룹
하나의 주소로 두개의 인스턴스에 접속 가능하다.
또다른 대상 그룹 생성하기
아무 인스턴스나 등록해서 second-target-group 을 생성했다.
리스너 설정하기
demo alb로 이동한다. 규치 보기/편집으로 간다 ( 현재 DemoELB는 first-target-group 으로 연결된다.)
만약 /test 경로를 입력하면 second-target-group으로 연결되게 한다.
/constant 에 연결하면 고정 에러 페이지가 나오게 한다.
여러가지 다른 방식으로 응답하게 설정했다.
test 로 접속하면 두번째 대상 그룹 화면이 떠야하는데 오류가 뜬다.
EC2 인스턴스가 /test 유형의 쿼리에 응답하도록 구성되지 않았기 때문이다.
정리
리스너 삭제
대상 그룹 두번째 삭제
첫번째 대상그룹에 나머지 인스턴스 추가
76. Network Load Balancer (NLB) 개요
Network Load Balancer (v2)
네트워크 로드 밸런서는 L4 로드 밸런서이미로 TCP, UDP 트래픽을 다룰 수 있다.
HTTP를 다루는 L7보다 하위 계층이다.
네트워크 로드 밸런서의 성능은 매우 높다.
초당 수백만 건의 요청을 처리할 수 있다.
애플리케이션 로드 밸런서에 비해 지연 시간도 짧다.
ALB는 400밀리초지만 NLB는 100 밀리 초이다.
가용 영역별로 하나의 고정 IP를 갖는다. NLB has one static IP per AZ, and supports assigning Elastic IP
탄력적 IP 주소를 각 AZ에 할당할 수 있다.
여러개의 고정 IP를 가진 애플리케이션을 노출할 때 유용하다.
1~3개의 ip로만 액세스할 수 있는 애플리케이션을 만들라는 문제가 나오면 네트워크 로드 밸런서를 옵션으로 고려하자!
고성능, TCP, UDP는 다 네트워크 로드 밸런서의 키워드이다.
NLB는 프리티어에 포함되지 않는다.
Network Load Balancer (v2) TCP (Layer 4 ) Based Traffic
대상 그룹을 생성하면 NLB 가 대상그룹을 리다이렉트한다.
백엔드, 프론트엔드 모두 TCP 트래픽을 사용하거나
백엔드에서는 HTTP를 , 프론트엔드에서는 TCP 를 사용할 수 있다.
Network Load Balancer - Target Groups 대상 그룹 유형
EC2 인스턴스 - 네트워크 로드밸런서가 TCP 또는 UDP 트래픽을 EC2 인스턴스로 리다이렉트 할 수 있다.
IP 주소 - IP주소는 반드시 하드코딩 되어야하고 프라이빗 IP여야한다. 주로 온프레미스가 대상이된다.
ALB - NLB는 고정된 IP를 가지고 ALB는 HTTP 유형의 트래픽을 처리할 수 있다.
상태 체크는 TCP, HTTP, HTTPS 프로토콜을 지원한다. (시험에 나온다.)
77. Gateway Load Balancer (GWLB) 개요
GWLB는 배포 및 확장과 aws의 타사 네트워크 가상 어플라이언스의 플릿 관리에 사용된다.
GWLB는 네트워크의 모든 트래픽이 방화벽을 통과하게 하거나 침입 탐지 및 방지 시스템에 사용한다.
IDPS 나 심층 패킷 분석 시스템 또는 일부 페이로드를 수정할 수 있지만 네트워크 수준에서 가능하다.
alb에서 애플리케이션으로 이동할 때 모든 트래픽을 검사하게 할려면 ?
유저와 어플리케이션 사이에 GWLB를 둔다. + 타사 가상 어플라이언스 배포
GWLB를 생성하면 이면에서는 VPC 에서 RT (라우팅 테이블) 이 업데이트 된다.
RT 가 업데이트 되었으므로 사용자의 모든 트래픽은 GWLB를 통과하고 -> 타사 가상 어플라이언스 -> GWLB -> 애플리케이션 순으로 트래픽이 이동한다.
방화벽이나 침입 탐지와 같은 것이다 .
원리는
GWLB는 IP 패킷의 네트워크 계층인 L3 이다.
기능
1. 투명한 네트워크 게이트웨이 ( 하나의 출입문 역할)
2. 로드 밸런서
6081 번 포트의 GENEVE 프로토콜
Gateway Load balancer - Target Groups
1. EC2 - 타사 어플라이언스
2. IP 주소 - 이 경우 개인 (private)IP 여야한다. 자체 네트워크나 자체 데이터 센터에서 이런 가상 어플라이언스를 실행하면 IP로 수동 등록할 수 있다.
하지만 활성화되어 비활성화할 수 없으니 ALB에서 AZ간 데이터 전송에 관한 비용이 업삳.
NLB는 교차 영역 로드 밸런싱이 비활성화되어 있기 때문에 az 간 데이터 이동에 대한 비용을 지불해야한다.
CLB 는 비활성화가 디폴트 이지만 활성화 후 az 간 데이터 전송은 무료이다.
80. Elastic Load Balancer( ELB) - 연결 트레이닝
연결 드레이닝 - Connection Draining
CLB - 연결 드레이닝
ALB, NLB- 등록 취소 지연 이라고 불린다.
인스턴스가 등록 취소, 혹은 비정상 상태에 있을 때 인스턴스에 어느 정도의 시간을 주어
인-플라이트 요청(in-flight request), 즉 활성 요청을 완료할 수 있도록 하는 기능이다.
ELB는 등록 취소 중인 EC2 인스턴스로 새로운 요청을 보내지 않는다.
1초에 3600초 까지 지연시간을 설정할 수 있다.
지연 시간을 0으로 설정하면 이 기능을 비활성화 할 수 있다.
짧은 요청의 경우에는 낮은 값으로 설정한다.
1초보다 적은 아주 짧은 요청인 경우에는 연결 드레이닝 파라미터를 30초 정도로 설정한다.
요청 시간이 매우 긴 요청은 높은 값을 지정한다.
81. Auto Scailing Group (ASG) 개요
What's an Auto Scaling Group?
웹사이트 방문자가 갈수록 많아지면서 워크로드가 바뀔 수 있다.
AWS 에서 EC2 인스턴스 생성 API 호출을 통해서 서버를 빠르게 생성하고 종료할 수 있다.
ASG는 해당 작업을 자동화한다.
ASG의 목적
Scale out - EC2 인스턴스를 늘리는 것
Scale in - EC2 인스턴스를 줄인다.
최소, 최대 인스턴스 수를 보장한다.
로드 밸런서와 페어링하는 경우 ASG에 속한 모든 EC2 인스턴스가 로드 밸런서에 연결된다.
인스턴스에 문제가 생기면 종료하고 새로운 인스턴스를 실행한다.
ASG 는 무료이다. 실행되는 ec2 인스턴스는 유료
Auto Scaling Group in AWS
minimum size : 최소
actual Size/ Desired capacity : 희망
Maximum size : 최대
Auto Scaling Group in AWS With Load Balancer
ASG는 LB와 좋은 조합이다.
사용자 -> ELB -> ASG -> EC2
ELB에서 EC2 instance 상태 체크가 가능하다.
상태에 문제가 있으면 종료 시키고 새로운 인스턴스를 생성하거나,
ELB가 트래픽을 ASG의 인스턴스로 분배한다.
Auto Scaling Group Attributes
ASG 에서 인스턴스를 추가할때 탬플릿을 기반으로 생성한다.
탬플릿에는 AMI, 인스턴스 타입, 사용자 데이터 ,EBS 볼륨, 보안 그룹, SSH key pair, IAM Roles for your EC2 Instances
Network + Subnets Information
Load balancer Information
등 다양한 정보를 가진다.
asg에서 최소, 최대, 초기 용량을 정해야한다.
스케일링 정책도 정해야한다 .
Auto Scaling - CloudWatch Alarms & Scaling
클라우드 워치 알람을 이용하여 asg의 스케일링을 이용할 수 있다.
metric 지표에 의해 경보를 울린다. ( average CPU, or a custom metric)
경보에 따라 인스턴스를 늘리거나 줄인다.
82. Auto Scaling Group ( ASG 실습)
오토 스케일링 그룹을 생성해보자!
1. 기존의 인스턴스 삭제
모두 종료
2. ASG 생성하기
DemoASG 로
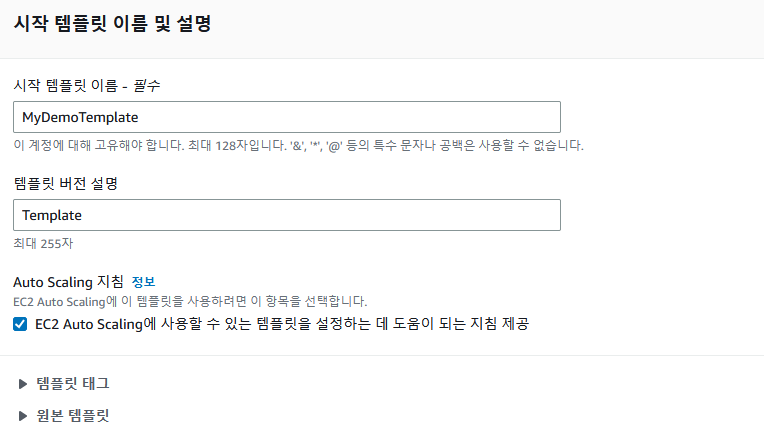
2-1 시작 템플릿 생성
#!/bin/bash
# Use this for your user data (script from top to bottom)
# install httpd (Linux 2 version)
yum update -y
yum install -y httpd
systemctl start httpd
systemctl enable httpd
echo "<h1>Hello World from $(hostname -f)</h1>" > /var/www/html/index.html
2-2 인스턴스 시작 옵션 선택
가용 영역은 3개 선택
시작 탬플릿 재정의에 여러 옵션을 덮어쓰기 할 수 있으나 패스한다.
2-3 고급 옵션 구성
기존 로드밸런서에 연결한다.
이미 생성했던 DemoALB 에 연결한다 .
ELB 에서도 상태 확인을 한다.
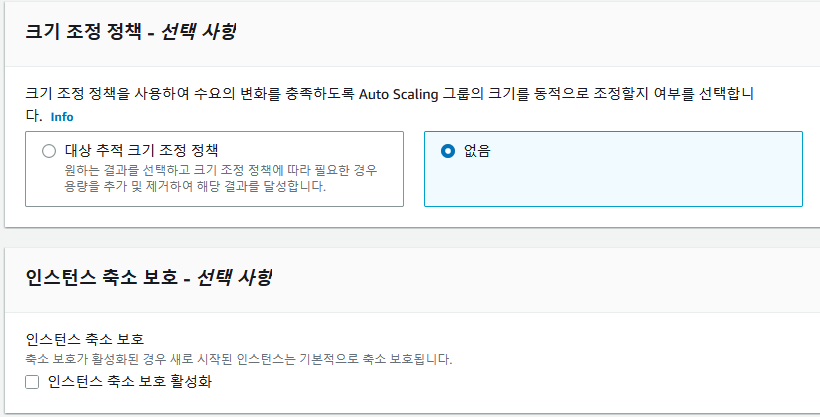
2-4 그룹 크기 및 크기 조정 정책 구성
asg의 크기를 정한다.
2-5 생성완료
생성 완료 되었다.
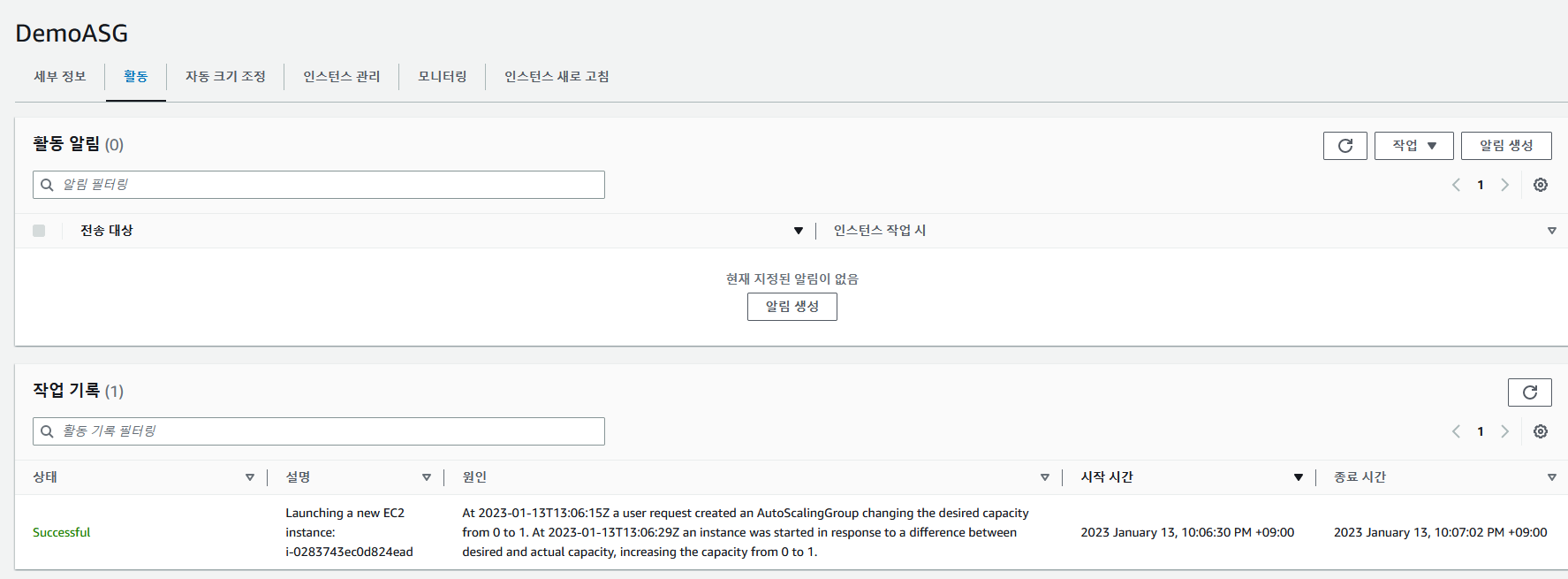
3. ASG 확인하기
최소 를 1로 했기 때문에 인스턴스가 작동한다.
DemoASG 인스턴스가 생성되었다.
asg 설정에서 ELB 를 선택했고 해당 ELB는 first-target-group 에 연결되어있고
해당 그룹은 DemoASG 인스턴스와 연결되어있다.
alb에 접속할 수 있다.
3-1 그룹 크기 변경해보자
2,2,4 로 변경했다..
인스턴스가 두개나 실행된다 .
인스턴스 2개에 접속한다.
마지막으로 크기를 1,1,1 로 변경한다.
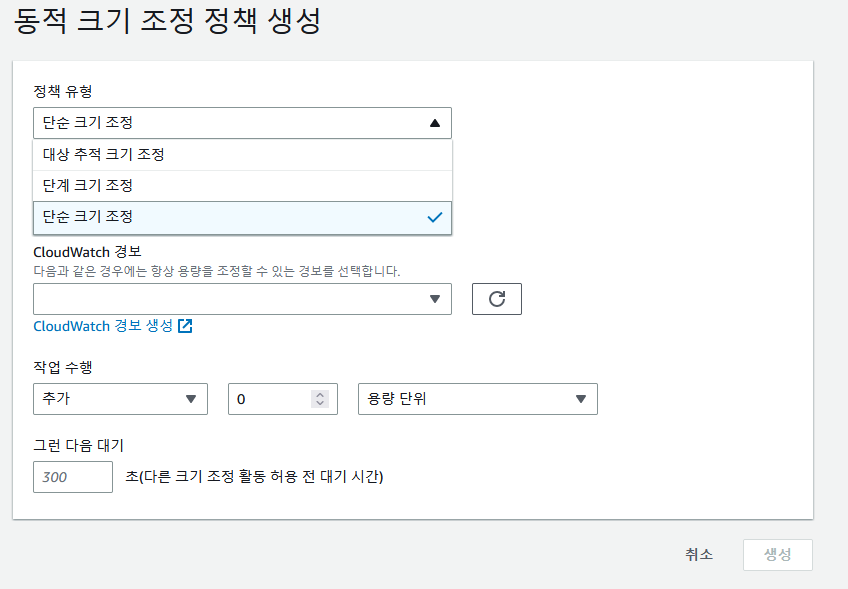
83. Auto Scaling Groups - Dynamic Scaling Policies
동적 확장 정책의 종류
1. 대상 추적 스케일링
가장 쉽다.
기본 기준선을 세우고 상시 가용 가능하도록한다.
ex) asg 평균 cpu 사용률이 40% 가 유지되게 한다.
2. 단순과 단계 스케일링
좀 복ㄱ잡하다
CloudWatch 경보를 설정하고 다음과 가팅
전체 ASG 에 대한 CPU 사용률이 70%를 초고하는 경우 용량을 두 유닛 추가하도록 설정한다.
~~ 30% 이하로 떨어지면 유닛 하나를 제거한다.
등의 설정을 할 수 있다.
단 CloudWatch 경보를 설정할 때에는 한 번에 추가할 유닛의 수와 한번에 제거할 유닛의 수를 단계별로 설정할 필요가 있다.
3. 예약된 작업 reserved Scaling
나와 있는 사용 패턴을 바탕으로 스케일링을 예상하는 것.
예를 들어 금요일 오후 5시에 큰 이벤트가 예정되어 있으니 여러 사람들이 애플리케이션을 사용하는 데에 대비해 여러분의 ASG 최소 용량을 매주 금요일 오후 5시마다 자동으로 10까지 늘린다.
4. 예측 스케일링 Predictive Scaling
예측 스케일링을 통해서 AWS 내 오토 스케일링 서비스를 활용하여 지속적으로 예측을 생성할 수 있다.
로드를 보고서 다음 스케일링을 예측한다.
시간에 걸쳐 과거 로드를 분석하고 예측이 생성된다.
해당 예측을 기반으로 사전에 스케일링 작업이 예약된다.
Good Metrics to scale one
지표로 삶기 좋은 항목
1. CPU 사용량
2. 요청 회수
3. 네트워크 입출력 ( 네트워크 과부하)
4. cloudWatch 에서 별도 지표를 직접 설정
Auto Scaling Groups - Scaling Cooldowns
스케일링 휴지 (Scaling cooldown)
- 스케일링 작업이 끝날 때마다 인스턴스의 추가 또는 삭제를 막론하고 기본적으로 5분 혹은 300초의 휴지 기간을 갖는다.
휴지 기간에는 ASG가 추가 인스턴스를 추가 또는 종료할 수 없다.
이는 지표를 활용하여 새로운 인스턴스가 안정화될 수 있도록 하며 어떤 새로운 지표의 양상을 살펴보기 위함이다.
따라서 스케일링 작업이 발생할 때에 기본으로 설정한 휴지가 있는지 확인해야한다.
조언: 즉시 사용이 가능한 AMI 를 이용하여 EC2 인스턴스 구성 시간을 단축하고 이를 통해 요청을 좀 더 신속히 처리하는 것이 좋다.
AWS에서 관리하는 기반 인프라가 변경되었다고 하더라도, AWS가 정적 엔드 포인트를 사용해 로드 밸런스로 액세스할 수 있기를 원하는 이유입니다.
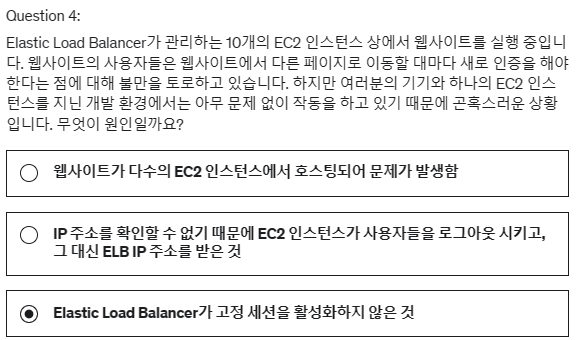
4. Elastic Load Balancer가 관리하는 10개의 EC2 인스턴스 상에서 웹사이트를 실행 중입니다. 웹사이트의 사용자들은 웹사이트에서 다른 페이지로 이동할 대마다 새로 인증을 해야한다는 점에 대해 불만을 토로하고 있습니다. 하지만 여러분의 기기와 하나의 EC2 인스턴스를 지닌 개발 환경에서는 아무 문제 없이 작동을 하고 있기 때문에 곤혹스러운 상황입니다. 무엇이 원인일까요?
ELB 고정 세션 기능은 동일한 클라이언트에 대한 트래픽이 항상 동일한 대상으로 리다이렉트되도록 해줍니다(예: EC2 인스턴스) 이는 클라이언트들이 세션 데이터를 소실하지 않게 해줍니다.
5. Application Load Balancer를 사용해 EC2 인스턴스에서 호스팅된 웹사이트의 트래픽을 분배하고 있습니다. 그런데 여러분의 웹사이트가 Application Load Balancer의 IP 주소인 사설 IPv4 주소에서 들어오는 트래픽만을 확인하고 있는 것으로 나타났습니다. 이런 경우, 웹사이트로 연결된 클라이언트들의 IP 주소를 받으려면 어떻게 해야 할까요?
Application Load Balancer를 사용하여 EC2 인스턴스에 트래픽을 배분하는 경우, 요청을 받게 되는 IP 주소는 ALB의 사설 IP 주소가 됩니다. 클라이언트의 IP 주소를 받기 위해, ALB는 클라이언트의 IP 주소를 포함하고 있는 X-Forwarded-For라는 헤더를 추가합니다.
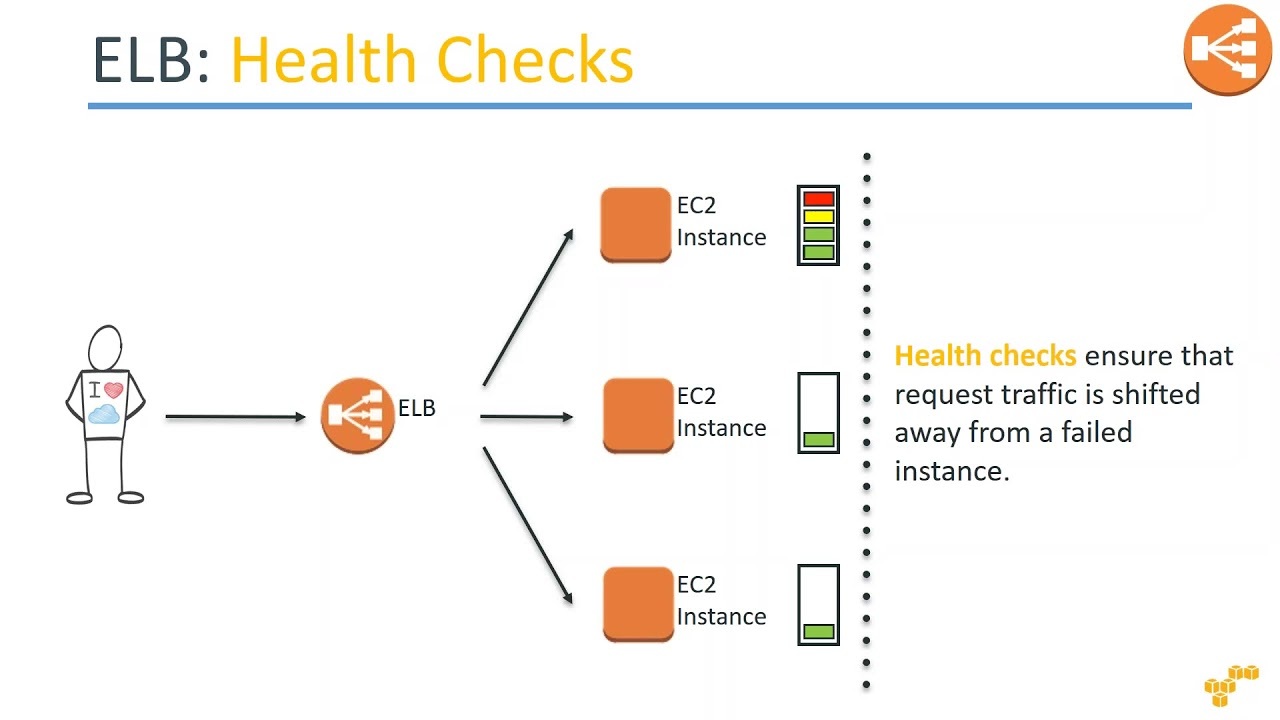
6. Elastic Load Balancer가 관리하는 한 세트의 EC2 인스턴스 상에 애플리케이션을 호스팅했습니다. 일주일 후, 사용자들은 가끔씩 애플리케이션이 작동하지 않는다며 호소하기 시작했습니다. 문제점을 조사한 결과, 일부 EC2 인스턴스가 이따금 충돌한다는 문제점이 발견되었습니다. 사용자들이 충돌하는 EC2 인스턴스에 연결되지 않도록 보호하기 위해서는 어떻게 해야 할까요?
ELB 상태 확인을 활성화하면, ELB가 비정상(충돌) EC2 인스턴스로는 트래픽을 보내지 않게 됩니다.
7. 어떤 기업에서 솔루션 아키텍트로 근무하고 있는 여러분은 1초에 수백만 개의 요청을 받게 될 고성능의, 그리고 지연 시간이 적은 애플리케이션을 위한 아키텍처를 설계해달라는 요청을 받았습니다. 다음 중 어떤 종류의 Elastic Load Balancer를 사용해야 할까요?
Network Load Balancer는 애플리케이션이 필요로 할 경우 가장 높은 성능과 가장 낮은 지연 시간을 제공합니다.
8. Application Load Balancer가 지원하지 않는 프로토콜을 고르세요.
9.Application Load Balancer는 트래픽을 다른 대상 그룹으로 라우팅할 수 있습니다. 이때 확인할 내용으로 사용할 수 없는 것을 고르세요
ALB는 URL 경로, 호스트 이름, HTTP 헤더 및 쿼리 문자열을 기반으로 트래픽을 다른 대상 그룹으로 라우팅할 수 있습니다.
10. Application Load Balancer의 대상 그룹에 등록된 대상이 될 수 없는 것을 고르세요.
11. 규정 준수를 위해, 고정된 정적 IP 주소를 최종 사용자에게 노출하여 사용자들이 안정적이고, 규제 기관의 승인을 받은 방화벽 규칙을 작성할 수 있도록 하려 합니다. 이런 경우, 다음 중 어떤 종류의 Elastic Load Balancer를 사용해야 할까요?
Network Load Balancer는 AZ 당 하나의 정적 IP 주소를 가지며, 여기에 탄력적 IP 주소를 연결할 수 있습니다. Application Load Balancer와 Classic Load Balancer를 정적 DNS 이름으로 사용할 수 있습니다.
12. Application Load Balancer 내에 사용자 지정 애플리케이션 기반 쿠키를 생성하려 합니다. 다음 중 쿠키의 이름으로 사용 가능한 것은 무엇인가요?
다음의 쿠키 이름은 ELB가 선점하고 있습니다(AWSALB, AWSALBAPP, AWSALBTG).
13. us-east-1에 있는 한 세트의 EC2 인스턴스에 트래픽을 배분하는 Network Load Balancer가 있습니다.us-east-1bAZ에 2개의 EC2 인스턴스,us-east-1eAZ에는 5개의 EC2 인스턴스가 있습니다. 여러분은us-east-1bAZ에 있는 EC2 인스턴스의 CPU 사용률이 더 높다는 것을 발견했습니다. 조사를 거친 결과, 두 개의 AZ에 걸쳐 분배된 트래픽의 양은 동일한 것으로 나타났습니다. 이 경우, 어떻게 문제를 해결해야 할까요?
영역간 로드 밸런싱을 활성화하면, ELB가 모든 AZ에 있는 등록된 EC2 인스턴스 전체에 동등하게 분배됩니다.
14. 다음 중 하나의 리스너로 다수의 SSL 인증서를 가져올 수 있도록 해주는 Application Load Balancer와 Network Load Balancer의 기능은 무엇인가요?
15. 다음과 같은 호스트 이름을 기반으로, 트래픽을 3개의 대상 그룹으로 리다이렉팅하도록 구성된 Application Load Balancer가 있습니다: users.example.com, api.external.example.com, checkout.example.com. 이 각각의 호스트 이름에 HTTPS를 구성하려 합니다. 이런 작업을 위해서는 ALB를 어떻게 구성해야 할까요?
16. 원하는 용량과 최대 용량을 모두 3으로 구성한 오토 스케일링 그룹에 의해 관리되고 있는, 한 세트의 EC2 인스턴스에 호스팅된 애플리케이션이 있습니다. 또한, CPU 사용률이 60%에 이르면 ASG를 스케일 아웃하도록 구성된 CloudWatch 경보도 생성해 뒀습니다. 해당 애플리케이션은 현재 갑자기 많은 양의 트래픽을 전송 받아 80% CPU 사용률에서 실행되고 있는 상태입니다. 이런 경우, 무슨 일이 일어나게 될까요?
오토 스케일링 그룹은 스케일 아웃 시, (구성된) 최대 용량을 넘어설 수 없습니다.
17. Application Load Balancer가 관리하는 오토 스케일링 그룹이 있습니다. ASG가 ALB 상태 확인을 사용하도록 구성을 해둔 상태인데, EC2 인스턴스가 비정상인 것으로 보고되었습니다. EC2 인스턴스에는 무슨 일이 일어나게 될까요?
오토 스케일링 그룹이 EC2 상태 확인(기본 설정)이 아닌 Application Load Balancer의 상태 확인을 기반으로 EC2 인스턴스의 상태를 판단하도록 구성할 수 있습니다. EC2 인스턴스가 ALB의 상태 확인에 실패할 경우, 이는 비정상인 것으로 표시되어 종료되며 ASG는 새로운 EC2 인스턴스를 실행합니다.
18. 여러분의 상사가 애플리케이션이 데이터베이스로 보내는 분당 요청 수를 기반으로 오토 스케일링 그룹을 스케일링하라고 요청했습니다. 어떻게 해야 할까요?
백엔드-데이터베이스 연결에는 ‘분당 요청'에 해당하는 CloudWatch 지표가 존재하지 않습니다. CloudWatch 경보를 생성하려면 CloudWatch 사용자 지정 지표를 먼저 생성해야 합니다.
19. 오토 스케일링 그룹 (ASG)에서 관리하는 EC2 인스턴스 플릿이 호스팅하는 웹 애플리케이션이 있습니다. 여러분은 애플리케이션 로드 밸런서 (ALB)를 통해 이 애플리케이션을 노출하고 있습니다. EC2 인스턴스와 ALB는 모두 다음 CIDR192.168.0.0/18을 사용하여 VPC에 배포됩니다. ALB만 포트80에서 액세스할 수 있도록 EC2 인스턴스의 보안 그룹을 구성하려면 어떻게 해야 할까요?
ALB만이 EC2 인스턴스로 액세스할 수 있게 할 수 있는 가장 안전한 방법입니다. 규칙에서 보안 그룹을 참조하는 것은 매우 강력한 규칙으로, 이 내용을 바탕으로 많은 시험 문제가 출제됩니다. 그러니 이에 관련된 내용은 반드시 숙지하도록 하세요!
20. eu-west-2리전에서 실행되는 오토 스케일링 구성이 있는데, 두 개의 가용 영역인eu-west-2a와eu-west-2b를 생성하도록 설정되어 있습니다. 현재eu-west-2a에는 3개의 EC2 인스턴스가 실행 중이며,eu-west-2b에는 4개의 EC2 인스턴스가 실행 중입니다. ASG는 스케일 인을 하려 합니다. 이들 중 어떤 EC2 인스턴스가 종료되게 될까요?
오토 스케일링 그룹의 기본 종료 정책을 반드시 기억해두세요. 이 정책은 우선 AZ에 걸친 밸런싱을 시도하며, 실행 구성이 오래된 순으로 종료합니다.
실행 템플릿이 제일 오래된 순으로 종료한다!
21. 애플리케이션은 Application Load Balancer와 오토 스케일링 그룹과 함께 배포됩니다. 현재 ASG를 수동으로 스케일링하고 있는 상태에서, EC2 인스턴스로의 평균 연결의 수를 1,000회 정도로 유지하기 위한 스케일링 정책을 정의하려 합니다. 이 중에서 어떤 스케일링 정책을 사용해야 할까요?
22. 오토 스케일링 그룹이 관리하는 EC2 인스턴스에 호스팅된 애플리케이션으로 들어오는 트래픽이 급격하게 증가하여, ASG가 스케일 아웃되고 새로운 EC2 인스턴스가 실행되게 되었습니다. 트래픽은 계속해서 증가하지만, ASG는 5분이 지나기 전까지는 새로운 EC2 인스턴스를 곧바로 실행하지 않습니다. 이런 경우, 가능성이 있는 원인은 무엇일까요?
오토 스케일링 그룹에는 각 스케일링 조치 이후 냉각 기간을 갖습니다. ASG는 냉각 기간 동안 EC2 인스턴스를 실행하거나 종료하지 않습니다. 이를 통해 지표들을 안정화시킬 수 있는 기간을 갖습니다. 냉각 기간의 기본 값은 300초(5분)입니다.
23. 지난 달, 어느 기업이 보유한 오토 스케일링 그룹 내의 무작위 EC2 인스턴스가 갑자기 충돌을 일으켰습니다. ASG가 비정상 EC2 인스턴스를 종료하고 이를 새로운 EC2 인스턴스로 대체하고 있는 관계로, EC2 인스턴스가 충돌하게 된 원인을 찾을 수 없는 상태입니다. 이 문제를 해결하고 ASG가 비정상 인스턴스를 종료하는 것을 막기 위해서는 어떤 문제 해결 조치를 취해야 할까요?
Amazon EC2 Auto Scaling은 오토 스케일링에 수명 주기 후크를 추가할 수 있는 기능을 제공합니다. 이러한 후크를 사용하면 Auto Scaling 인스턴스 수명 주기의 이벤트를 인식하는 솔루션을 생성한 다음 해당 수명 주기 이벤트가 발생할 때 인스턴스에 대한 사용자 정의 작업을 수행할 수 있습니다. 수명 주기 후크는 인스턴스가 다음 상태로 전환되기 전에 작업이 완료될 때까지 대기할 지정된 시간(기본적으로 1시간)을 제공합니다.