
118. Cluster Maintenance - Section Introduction

클러스터 유지 관리와 관련된 주제를 다룰 것이다.
운영 체제 업그레이드
백업과 복원 방법론을 배울 것이다.
120. Operation System Upgrade

노드를 제거해야하는 상황에 대해 알아보자 (업그레이드할 때 등등)

2번 노드에 파랑, 초록 포드가 있었는데 꺼졌다.
그럴땐 어떻게 해야할까?
보통은 노드를 다시 복구시킨다. 하지만 5분 넘게 노드가 다운되면 노드에 있던 포드는 삭제된다.
pod-eviction-timeout
node가 다시 복구할때까지 3,4번 노드가 대신 포드를 작동 시켜준다.
kube-controller-manager --pod-eviction-timeout=5m0s
만약 노드가 계속 복구 안될 것 같은 경우에는 포드를 다른 노드로 옮기는 것이 안전하다.

drain 을 통해서 워크로드를 노드로 옮길 수 있다.
실제로 옮겨지는게 아니다. 파드가 삭제되고 새로이 생성되는 것이다.

cordon을 통해서 해당 노드에 새 파드 배치를 막을 수 있다.

uncordon을 통해서 금지를 풀 수 있다.
121. Practice Test - OS Upgrades
1.
Let us explore the environment first. How many nodes do you see in the cluster?
Including the controlplane and worker nodes.

2개
2.
How many applications do you see hosted on the cluster?
Check the number of deployments in the default namespace.

1개
3.
Which nodes are the applications hosted on?

4.
We need to take node01 out for maintenance. Empty the node of all applications and mark it unschedulable.
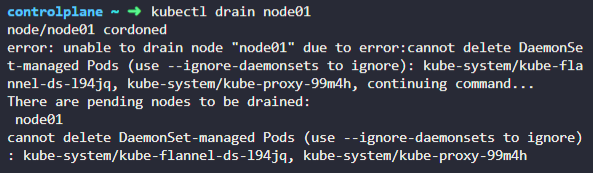
cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore)
daemonset 옵션을 꺼야한다.

5.
What nodes are the apps on now?

controlplane
6.
The maintenance tasks have been completed. Configure the node node01 to be schedulable again.

7.
How many pods are scheduled on node01 now?

0개
8.
Why are there no pods on node01?

9.
Why are the pods placed on the controlplane node?
Check the controlplane node details.

10.
Time travelling to the next maintenance window…
11.
We need to carry out a maintenance activity on node01 again. Try draining the node again using the same command as before:
kubectl drain node01 --ignore-daemonsets
Did that work?


12.
Why did the drain command fail on node01? It worked the first time!

node01 에 pod hr-app 이 돌아가고 있기 때문
13.
What is the name of the POD hosted on node01 that is not part of a replicaset?

14.
What would happen to hr-app if node01 is drained forcefully?
Try it and see for yourself.
사라진다 .
15.
Oops! We did not want to do that! hr-app is a critical application that should not be destroyed. We have now reverted back to the previous state and re-deployed hr-app as a deployment.
16.
hr-app is a critical app and we do not want it to be removed and we do not want to schedule any more pods on node01.
Mark node01 as unschedulable so that no new pods are scheduled on this node.
Make sure that hr-app is not affected.

node01 에 다른 포드가 돌아가고 있다. 포드를 계속 운영하고 다른 포드가 node01 에 올라오지 않게 설정한다
cordon
123. Kubernetes Software Vesrions

쿠버네티스 클러스터를 설치하면 특정 버전의 쿠버네티스를 설치하게 된다.


major, minor, patch 로 바뀐다.




124. References
https://kubernetes.io/docs/concepts/overview/kubernetes-api/
Here is a link to kubernetes documentation if you want to learn more about this topic (You don't need it for the exam though):
125. Cluster Upgrade Process

쿠버네티스 클러스터 업그레이드 프로세스에 대해 배워보자

쿠버네티스는 버전마다 다른 기능을 제공한다.

가장 기본이 되는 버전을 확인해보자
kube-api server 모든 컴포넌트랑 통신하기 때문에 kube-api server 보다 버전이 같거나 낮아야한다.
컨트롤 매니저, 스케쥴러는 kube api 보다 한단계 낮음 ok
kubelet, kube-proxy는 kube api 보다 두단계 까지 낮음 ok
kubectl 도구는 kube api 보다 한 단계 높거나 낮아도 된다. + - 1

Kubernetes supports only up to the recent three minor versions.
쿠버네티스는 최근 마이너 세개까지 버전을 지원한다.
업데이트할때 다이렉트로 업데이트 1.10 -> 1.13 업데이트 하는 것이 아니라 1.10 -> 1.11 -> 1.12 -> 1.13 이렇게 이동한다

업그레이드 방법은 셋업에 따라 다르다.
클라우드 서비스 (아마존, gcp) 같은 경우 손쉽게 업그레이드 할 수 있다.
kubeadm 을 사용하면 위의 명령어로 업그레이드 할 수 있다.
직접 쿠버네티스를 구현했으면 하드 코딩으로 업그레이드 해야한다.
당연히 kubeadm 을 사용한 업그레이드 방법을 배워볼 것이다.

( 마스터노드도 v1.10 이었다.)
마스터 노드를 먼저 업그레이드 시키고 워커 노드를 업그레이드 한다.
마스터노드를 중지시키고 업데이트 시킨다. 이때 마스터 노드의 kube api, 스케줄러, 컨틀롤러등 다운된다.
워커 노드는 계속 작동 중
워커 노드에 문제가 생겨도 컨트롤 매니저가 꺼져있기 때문에 그냥 나둬야함.

워커노드를 업데이트 하는 첫번째 방법은 모두 한번에 변경하는 것이다.
대신 모든 서비스가 안되는 down time 을 갖게 된다 .

마스터 노드를 업그레이드 시킨 후 노드를 하나씩 업그레이드 한다 .


마지막에 업데이트 완료

세번째 방법은 하나씩 새버전의 노드를 추가하는 방법이다 .
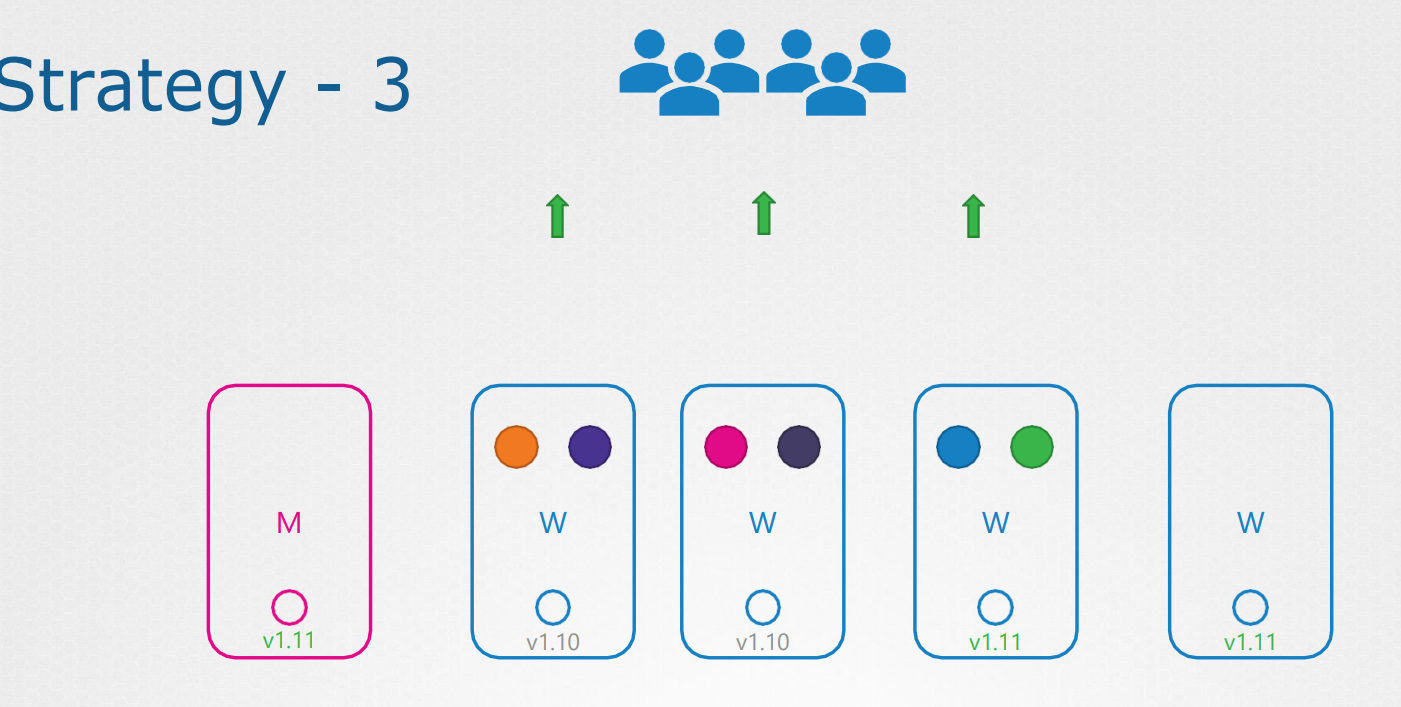
기존의 포드를 새로운 노드에 옮기고 삭제 -> 반복한다

kubeadm upgrade plan 명령을 통해서 업그레이드 관련 정보를 확인할 수 있다.

만약 업그레이드 하고 싶다면 kubeadm 도 마찬가지로 버전 업해야한다. 1.13.4

먼저 버전 1.12로 업그레이드
get 파드에서 1.11.3 버전이라고 뜬다?
api 서버 자체의 버전이 아니라 api 서버로 등록된 각각의 노드에서 버전의 kublets 을 보여주고 있기 때문
다음 단계는 kublet을 업그레이드 하는 것이다.

마스터 노드의 버전이 업데이트 되었다.

워커 노드는 drain 명령어로 포드를 이사보낸다.
마지막엔 uncordon으로 노드를 푼다.
각 워커 노드를 drain 시키고 uncordon으로 푸는 중간에
apt-get upgrade -y kubeadm=1.12.0-00apt-get upgrade -y kubelet=1.12.0-00kubeadm upgrade node config --kublet-version v1.12.0systemctl restart kubelet명령어들을 통해 워커 노드를 업데이트 시킨다.
126. Demo- Cluster upgrade
https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
Upgrading kubeadm clusters
This page explains how to upgrade a Kubernetes cluster created with kubeadm from version 1.25.x to version 1.26.x, and from version 1.26.x to 1.26.y (where y > x). Skipping MINOR versions when upgrading is unsupported. For more details, please visit Versio
kubernetes.io
클러스터 업데이트 시키는 방법 실습 내용이다
katakoda 에서 playground를 제공했으나 서비스가 중지되었다.
cat /etc/#release* 명령어로 운영 체제 버전을 확인한다.
Upgrade kubelet and kubectl
# replace x in 1.25.x-00 with the latest patch version
apt-mark unhold kubelet kubectl && \
apt-get update && apt-get install -y kubelet=1.25.x-00 kubectl=1.25.x-00 && \
apt-mark hold kubelet kubectl
Upgrading control plane nodes
upgrade kubeadm:
# replace x in 1.25.x-00 with the latest patch version
apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm=1.25.x-00 && \
apt-mark hold kubeadm
verify that the download works and has the expected version
kubeadm versionkubeadm 버전을 확인하고
Verify the upgrade plan
kubeadm upgrade plan해당 버전에서 업그레이드 할 수 있는 요소들이 뜬다 .
+-1 버전들
Choose a version to upgrade to , and run the appropriate command. For example:
sudo kubeadm upgrade apply v1.25.x업그레이드가 진행된다.
your cluster was upgraded to "xxx" 가 뜬다.
버전을 확인하면 여전히 전 버전으로 뜬다.
kubeadm은 업데이트 했지만 kubelet 이 업데이트 안되었음.
Drain the node
kubelet 노드를 업그레이드 하기 전에 비운다.
# replace <node-to-drain> with the name of your node you are draining
kubectl drain <node-to-drain> --ignore-daemonsetsUpgrade kubelet and kubectl
upgrade the kubelet and kubectl
# replace x in 1.25.x-00 with the latest patch version
apt-mark unhold kubelet kubectl && \
apt-get update && apt-get install -y kubelet=1.25.x-00 kubectl=1.25.x-00 && \
apt-mark hold kubelet kubectl다시 업데이트
Restart the kubelet
sudo systemctl daemon-reload
sudo systemctl restart kubelet노드의 버전을 확인하면 이제 변경되었을 것 이다.
Uncordon the node
# replace <node-to-uncordon> with the name of your node
kubectl uncordon <node-to-uncordon>해당 노드를 다시 연다 .
Upgrade worker nodes 작업자 노드 업데이트 하기
Upgrade kubeadm
upgrade kubeadm:
# replace x in 1.25.x-00 with the latest patch version
apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm=1.25.x-00 && \
apt-mark hold kubeadm작업자 노드로 접속한 후 업데이트 한다.
Call "kubeadm upgrade"
sudo kubeadm upgrade nodekubeadm 을 업그레이드 한 후
Drain the node
# replace <node-to-drain> with the name of your node you are draining
kubectl drain <node-to-drain> --ignore-daemonsets노드 비우기
노드 비울때 controlplane 에서 실행해야한다.
Upgrade kubelet and kubectl
# replace x in 1.25.x-00 with the latest patch version
apt-mark unhold kubelet kubectl && \
apt-get update && apt-get install -y kubelet=1.25.x-00 kubectl=1.25.x-00 && \
apt-mark hold kubelet kubectl
Restart the kubelet:
sudo systemctl daemon-reload
sudo systemctl restart kubelet데몬과 kubelet을 재시작한다.
Uncordon the node
# replace <node-to-uncordon> with the name of your node
kubectl uncordon <node-to-uncordon>노드 풀기
이것도 controlplane 에서 실행해야한다.
127. Practice Test - Cluster Upgrade
1.This lab tests your skills on upgrading a kubernetes cluster. We have a production cluster with applications running on it. Let us explore the setup first.
What is the current version of the cluster?

v1.25.0
2. How many nodes are part of this cluster?
Including controlplane and worker nodes
2개
3. How many nodes can host workloads in this cluster?Inspect the applications and taints set on the nodes.

2개
4. How many applications are hosted on the cluster? Count the number of deployments in the default namespace.

1개
5. What nodes are the pods hosted on?
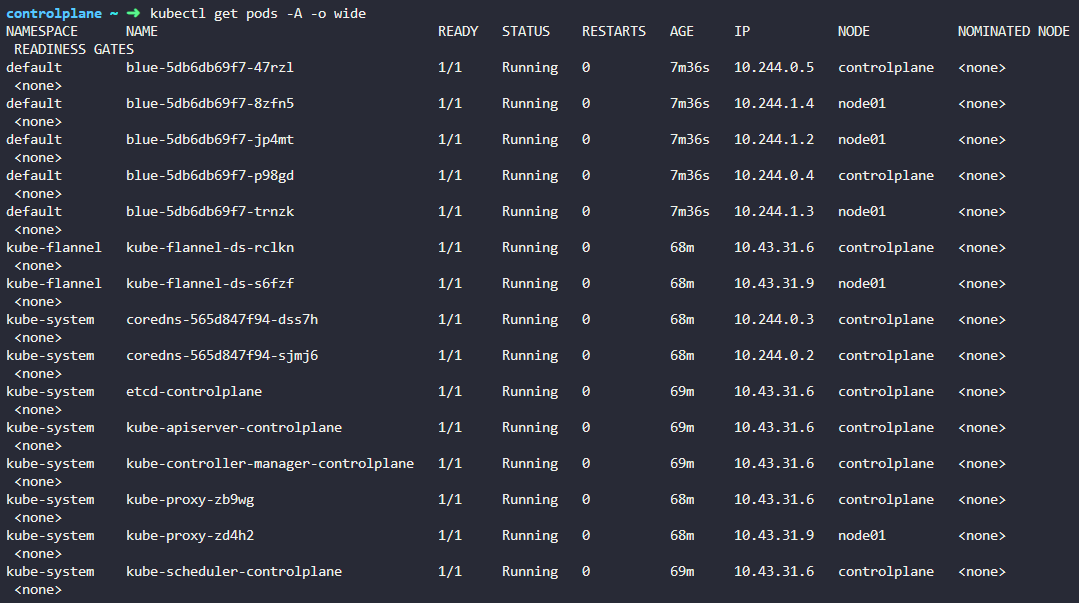
6. You are tasked to upgrade the cluster. Users accessing the applications must not be impacted, and you cannot provision new VMs. What strategy would you use to upgrade the cluster?
1. Upgrade one node at a time while moving the workloads to the other
1번
7. What is the latest stable version of Kubernetes as of today? Look at the remote version in the output of the kubeadm upgrade plan command.

1.26.1 이 최신 버전이다.
8. What is the latest version available for an upgrade with the current version of the kubeadm tool installed? Use the kubeadm tool

1.25.6
9. We will be upgrading the controlplane node first. Drain the controlplane node of workloads and mark it UnSchedulable

10. Upgrade the controlplane components to exact version v1.26.0 Upgrade the kubeadm tool (if not already), then the controlplane components, and finally the kubelet. Practice referring to the Kubernetes documentation page.
Note: While upgrading kubelet, if you hit dependency issues while running the apt-get upgrade kubelet command, use the apt install kubelet=1.26.0-00 command instead.
apt update
apt-cache madison kubeadm
apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm=1.26.0-00 && \
apt-mark hold kubeadm-
kubeadm version
kubeadm upgrade plan# replace x with the patch version you picked for this upgrade
sudo kubeadm upgrade apply v1.26.0
apt-mark unhold kubelet kubectl && \
apt-get update && apt-get install -y kubelet=1.26.0-00 kubectl=1.26.0-00 && \
apt-mark hold kubelet kubectl
sudo systemctl daemon-reload
sudo systemctl restart kubelet
11. Mark the controlplane node as "Schedulable" again

노드를 푼다 .
12. Next is the worker node. Drain the worker node of the workloads and mark it UnSchedulable

13. Upgrade the worker node to the exact version v1.26.0
ssh 로 노드에접속

apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm=1.26.0-00 && \
apt-mark hold kubeadm
sudo kubeadm upgrade node# replace x in 1.25.x-00 with the latest patch version
apt-mark unhold kubelet kubectl && \
apt-get update && apt-get install -y kubelet=1.26.0-00 kubectl=1.26.0-00 && \
apt-mark hold kubelet kubectl-
sudo systemctl daemon-reload sudo systemctl restart kubelet
kubectl uncordon <node-to-uncordon>
14. Remove the restriction and mark the worker node as schedulable again.

129. Backup and Restore Methods
| Backup Candidates

구성파일, ETCD, 백업 장소 키워드를 생각하면서 해보자
| Imperative

명령적인 방법으로 개체를 구성하기
| Declarative

선언적 방법으로는 구성파일을 생성한 후 apply 명령어로 실행
소스 코드를 리포지토리에 저장하는 것이 좋다.
| Backup - Resource Configs 구성 파일을 백업하는 또 다른 방법

kubectl get all --all-namespaces -o yaml > all-deploy-services.yaml모든 네임 스페이스에서 모든 객체를 가져와서 all-deploy-services.yaml 파일에 담는다.
벨레로라 라는 도구를 이용해 쿠버네티스 API를 이용해 쿠버네티스 클러스터 백업을 가져오는 데 도움이 된다 .
| Backup - ETCD

ETCD 에 클러스터 자체에 관한 정보와 노드 및 클러스터 내부에서 생성된 모든 리소스가 여기 저장된다.
리소스를 백업하는 대신 기타 서버 자체를 백업할 수 있다?

모든 마스터노드에 ETCD 가 숨어있다.
ETCD 가 보관된 디렉토리를 이용한다

또는 ETCD는 built in 스냅샷을 지원한다.
스냅샷 기능을 이용해 데이터베이스 스냅샷을 찍을 수 있다.
명령어를 통해서 백업의 상태를 볼 수 있다.


스냅샷을 복원하기에 앞서 kube-apiserver를 중지해야한다.
snapshot restore snapshot.db
스냅샷 복원을 실시한다.
복원을 실시하면 새로운 클러스터에 새로운 구성 맴버를 초기화시킨다.
(기존 작동 중인 클러스터에 초기화 되면 안되므로)
/var/lib/etcd-from-backup 경로에 새 데이터 디렉터리가 생성된다.


daemon을 다시 실행 시킨다 .
서비스도 마찬가지
kube-apiserver 도 실행

인증서 파일을 지정하는 걸 기억하자!
130. Working with ETCDCTL
etcdctl etcd에 대한 명령줄 클라이언트입니다.
모든 쿠버네티스 핸즈온 랩에서 ETCD 키-값 데이터베이스는 마스터의 정적 파드로 배포된다. 사용 된 버전은 v3입니다.
백업 및 복원과 같은 작업에 etcdctl을 사용하려면 ETCDCTL_API 3으로 설정해야 합니다.
etcdctl 클라이언트를 사용하기 전에 변수 ETCDCTL_API 내보내면 됩니다. 이 작업은 다음과 같이 수행 할 수 있습니다.
export ETCDCTL_API=3
마스터 노드에서:

특정 부속 명령에 대한 모든 옵션을 보려면 -h 또는 --help 플래그를 사용하십시오.
예를 들어, etcd의 스냅샷을 찍으려면 다음을 사용합니다.
etcdctl snapshot save -h 그리고 필수 전역 옵션을 기록해 두십시오.
당사의 ETCD 데이터베이스는 TLS를 지원하므로 다음 옵션이 필수입니다.
--cacert 이 CA 번들을 사용하여 TLS 사용 보안 서버의 인증서 확인
--cert 이 TLS 인증서 파일을 사용하여 보안 클라이언트 식별
--endpoints=[127.0.0.1:2379] 이는 ETCD가 마스터 노드에서 실행 중이고 로컬 호스트 2379에 노출되므로 기본값입니다.
--key 이 TLS 키 파일을 사용하여 보안 클라이언트 식별
마찬가지로 스냅샷 복원에 대한 도움말 옵션을 사용하여 백업 복원에 사용할 수 있는 모든 옵션을 확인합니다.
etcdctl snapshot restore -h
etcdctl 명령행 도구를 사용하고 -h 플래그로 작업하는 방법에 대한 자세한 설명은 백업 및 복원 랩의 솔루션 비디오를 확인하십시오.
=> etcdctl 참고하자!
131. Practice Test - Backup and Restore Methods
1. We have a working kubernetes cluster with a set of applications running. Let us first explore the setup. How many deployments exist in the cluster?

2개
2. What is the version of ETCD running on the cluster? Check the ETCD Pod or Process

etcd-controlplane을 확인하고

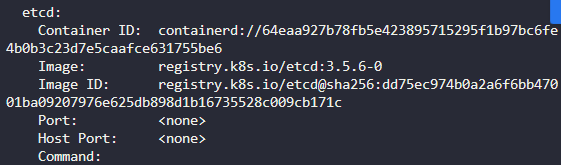
버전 3.5.6 쯤 된다.
3. At what address can you reach the ETCD cluster from the controlplane node? Check the ETCD Service configuration in the ETCD POD

커맨드 부분을 확인하면 listen-client-urls 에 127.0.0.1:2379 로 통신 가능
4. Where is the ETCD server certificate file located? Note this path down as you will need to use it later

커맨드 위쪽에 확인 가능
/etc/kubernetes/pki/etcd/server.crt
5. Where is the ETCD CA Certificate file located? Note this path down as you will need to use it later.

6. The master node in our cluster is planned for a regular maintenance reboot tonight. While we do not anticipate anything to go wrong, we are required to take the necessary backups. Take a snapshot of the ETCD database using the built-in snapshot functionality.
Store the backup file at location /opt/snapshot-pre-boot.db

yaml 파일 확인


etcd-data 디렉토리 확인
--data-dir=/var/lib/etcd

해당 디렉토리에는 맴버라고 뜬다.

etcdctl 을 그냥 쓰고 싶으면 export api 를 먼저 해준다.

cacert, cert, key 파일 위치를 다 받고 저장할 디렉토리를 지정한다.
엔드포인트는 etcd가 통신하는 엔드포인트
7. Great! Let us now wait for the maintenance window to finish. Go get some sleep. (Don't go for real)
Click Ok to Continue
8. Wake up! We have a conference call! After the reboot the master nodes came back online, but none of our applications are accessible. Check the status of the applications on the cluster. What's wrong?

all of the above
9. Luckily we took a backup. Restore the original state of the cluster using the backup file.




yaml 파일을 수정하면 적용된다.
kubectl delete pod etcd-controlplane -n kube-system
133. Practice Test Backup and Restore Methods 2
1. In this lab environment, you will get to work with multiple kubernetes clusters where we will practice backing up and restoring the ETCD database.
2. You will notice that, you are logged in to the student-node (instead of the controlplane).
The student-node has the kubectl client and has access to all the Kubernetes clusters that are configured in thie lab environment.
Before proceeding to the next question, explore the student-node and the clusters it has access to.

student-node 로 로그인 되어있음.
3. How many clusters are defined in the kubeconfig on the student-node?
You can make use of the kubectl config command.
kubectl config get-clusters
또는
kubectl config view 로 확인가능

2개
4. How many nodes (both controlplane and worker) are part of cluster1?
Make sure to switch the context to cluster1:
kubectl config use-context cluster1

2개
5. What is the name of the controlplane node in cluster2? Make sure to switch the context to cluster2:
kubectl config use-context cluster2

cluster2-controlplane
6. You can SSH to all the nodes (of both clusters) from the student-node.
노드로 접속할 수 있다.
ctrl + D 로 나가기 가능
7. How is ETCD configured for cluster1? Remember, you can access the clusters from student-node using the kubectl tool. You can also ssh to the cluster nodes from the student-node.
Make sure to switch the context to cluster1:

stacked ETCD 로 구성된다.
8. How is ETCD configured for cluster2? Remember, you can access the clusters from student-node using the kubectl tool. You can also ssh to the cluster nodes from the student-node.
Make sure to switch the context to cluster2:
kubectl config use-context cluster2
여기에는 없다.

cluster2-controlplane 로 접속

external etcd 존재
9. What is the IP address of the External ETCD datastore used in cluster2?

10.13.144.19
10.What is the default data directory used the for ETCD datastore used in cluster1?
Remember, this cluster uses a Stacked ETCD topology.
Make sure to switch the context to cluster1:
kubectl config use-context cluster1