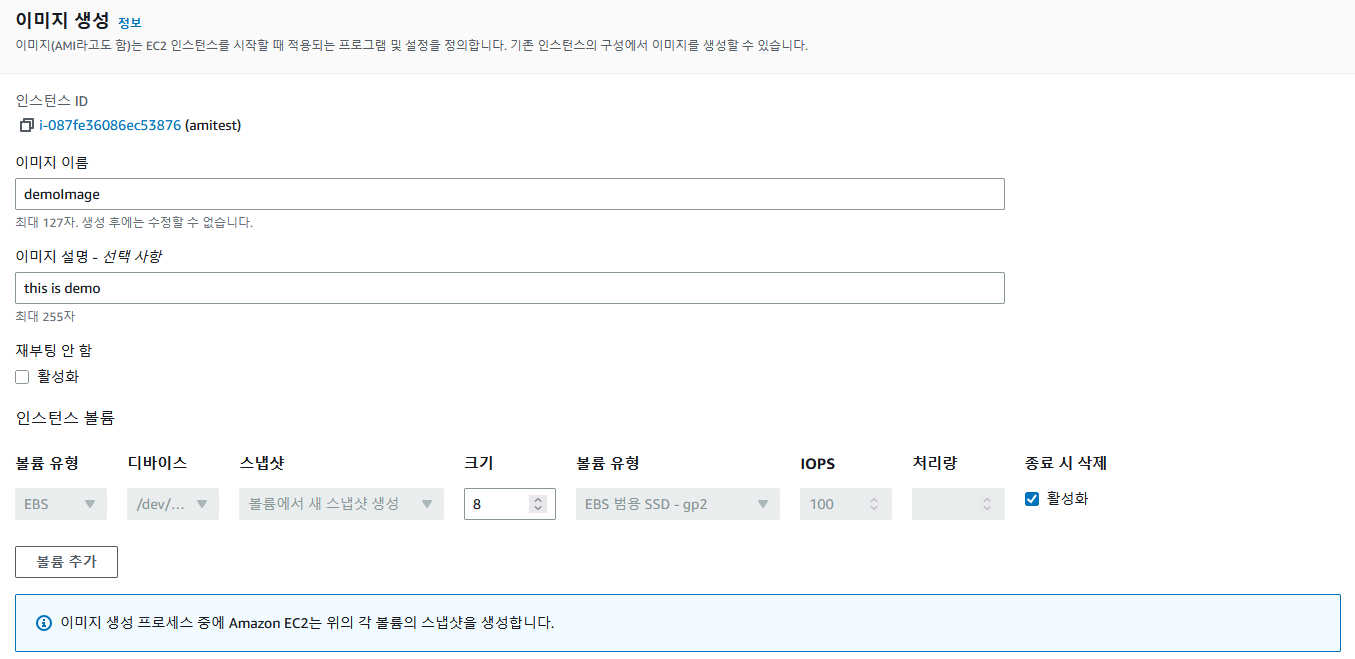
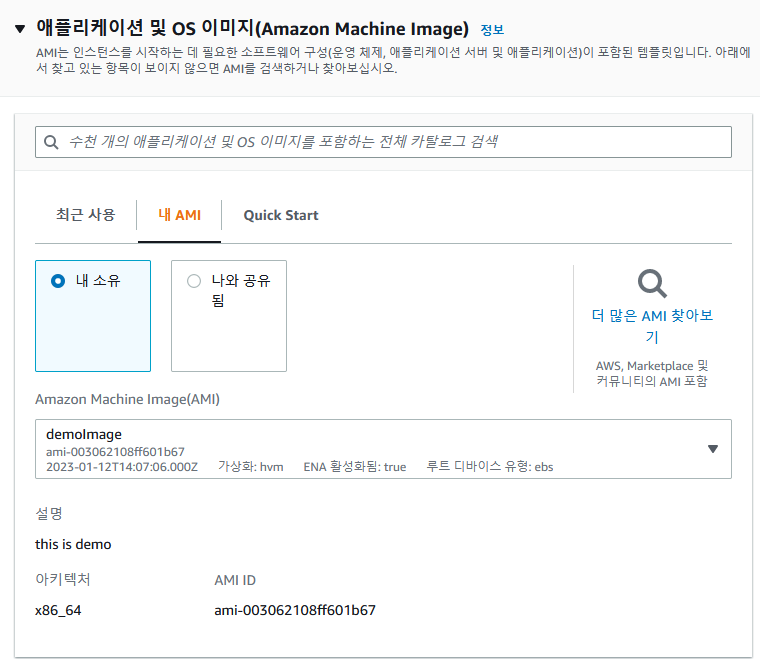
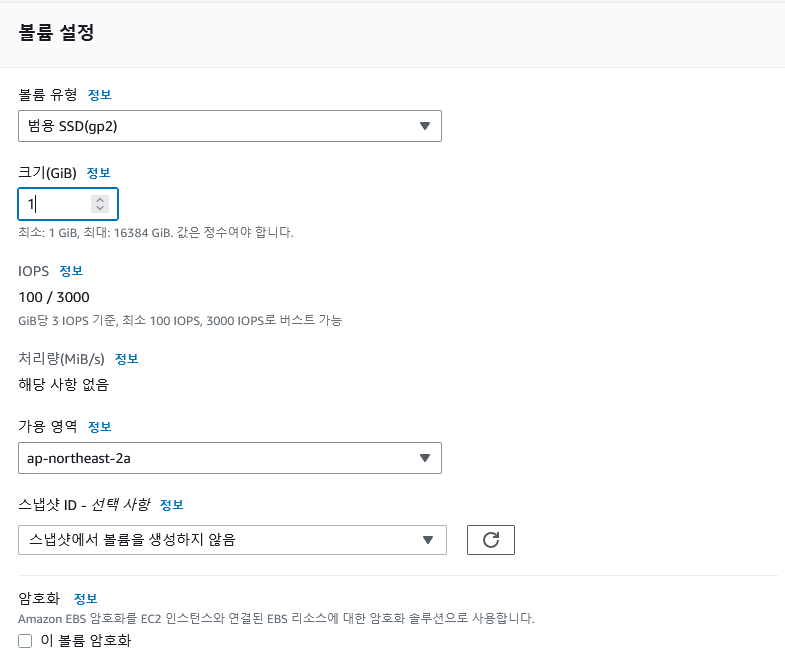
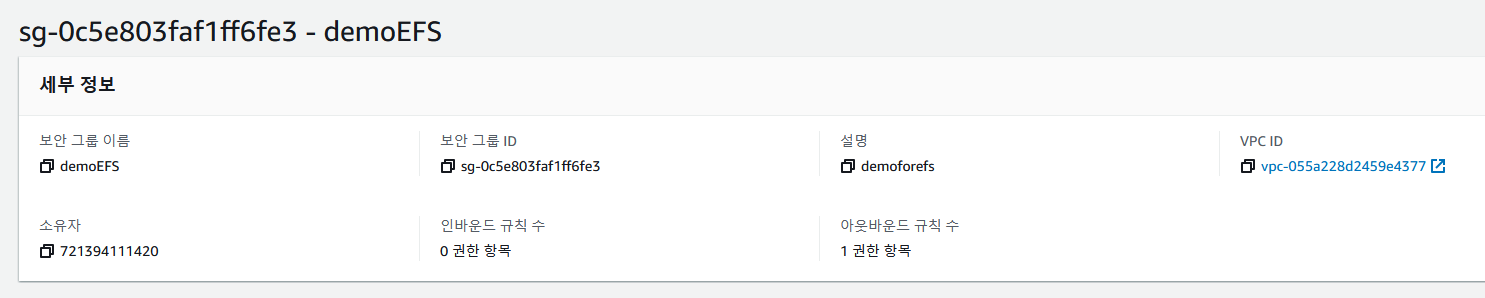
【한글자막】 AWS Certified Solutions Architect Professional | Udemy
2023.01.06 - [DevOps/aws] - Udemy | AWS Certified Solutions Architect Associate 강의 | Section1~2
2023.01.09 - [DevOps/aws] - AWS Certified Solutions Architect Associate 강의 Udemy | Section 5: EC2 기초
99. DNS 란 무엇일까요?
What is DNS?
호스트 네임을 IP로 변환 한다.
www.google.com -> 172.217.18.36
인터넷의 중추
계층적 이름 구조이다. (DNS uses hieracrchical naming structure)
.com
example.com
DNS Terminologies
Domain Registrar
도메인을 등록하는 곳
DNS 레코드
A, AAAA, CNAME, NS 등 있다.
Zone File
모든 DNS Record를 포함한다 .
Name 서버
DNS 쿼리를 실제로 해결하는 서버
Top Level Domain (TLD) : com, us, in ,gov, org ....
Second Level Domain( SLD) : amazon.com, google.com

FQDN (Fully Qualified Domain Name)
How DNS Works

webserver www.example.com에 에 접속한다고 가정하자.
1. 클라이언트에서 해당 주소를 DNS resolver에 물어본다. ( 보통 통신사에서 운영 ).
2. DNS resolver 가 dns root server에 물어본다.
3. 그리고 TLD 서버에 물어본다.
4. Route53 같은 SLD 에 물어본다.
5. ip 주소를 받으면 클라이언트에서 웹서버로 바로 접속한다 .
100. Amazon Route 53 개요
Amazon Route 53
고가용성, 확장성을 갖춘 , 완전히 관리가되며 권한이 있는 DNS 이다 .
권한이 있다는건? -> DNS 레코드를 업데이트 할 수 있다.
DNS에 대한 완전히 제어가 가능하다.

Route53 역시 도메인 이름 레지스트로 도메인 이름을 myrealcode.com 으로 등록한다.
Route53의 리소스 관련 상태를 확인할 수 있다.
100%SLA 가용성을 제공하는 유일한 aws 서비스이다 .
53은 전통적인 DNS 포트이다 .
Route 53 - Records
레코드를 통해 특정 도메인으로 라우팅하는 방법을 정의한다.
각 레코드는 도메인이나 example.com 과 같은 서브도메인 이름과 같은 정보를 포함한다.
예를 들어 A 나 AAAA가 있다
레코드의 값은 123.456.789.123 인데 라우팅 정책은 Route53이 쿼리에 응답하는 방식이다.
TTL은 DNS 리졸버에서 레코드가 캐싱되는 시간이다.
반드시 알아야하는것
A /AAAA/ CNAME/ NS
고급
CAA/DS / MX/ NAPTR/ PTR/ SOA/ TXT/ SPF / SRV
Route 53 - Record Types
A - map to IPv4
AAAA - map to IPv6
CNAME - maps a hostname to another hostname
A, AAAA 가 되어야한다.
Route 53 에서 DNS 이름 공간 또는 Zone Apex의 상위 노드에 대한 CNAMES 를 생성할 수 없다.
example.com 에 CNAME 을 만들 수 없지만 www.example.com 에 대한 CNAME은 만들 수 있따.
NS - Name Servers for the Hosted Zone
호스팅 존의 네임서버이다.
서버의 DNS 이름 또느 IP 주소로 호스팅 존에 대한 DNS 쿼리에 응답 할 수 있다.
또한 트래픽이 도메인으로 라우팅 되는 방식을 제어한다.
Route 53 - Hosted Zones
호스팅 존은 레코드의 컨테이너이다.
도메인과 서브도메인으로 가는 트래픽의 라우팅 방식을 정의한다.
호스팅 존의 종류
퍼블릭 호스팅 존 - 인터넷에서 어떻게 라우트 되어야하는지에 대한 정보를 담고 있다. application1.mypublicdomain.com
프라이빗 호스팅 존- VPC 에서 사용가능 application1.company.internal
AWS 에서 만드는 어떤 호스팅 존이든 월에 50 센트를 지불해야한다.
Route 53 - Public vs Private Hosted Zones

프라이빗 호스팅 존은 프라이빗 IP 를 알려준다. VPC 에서만 작동한다 .
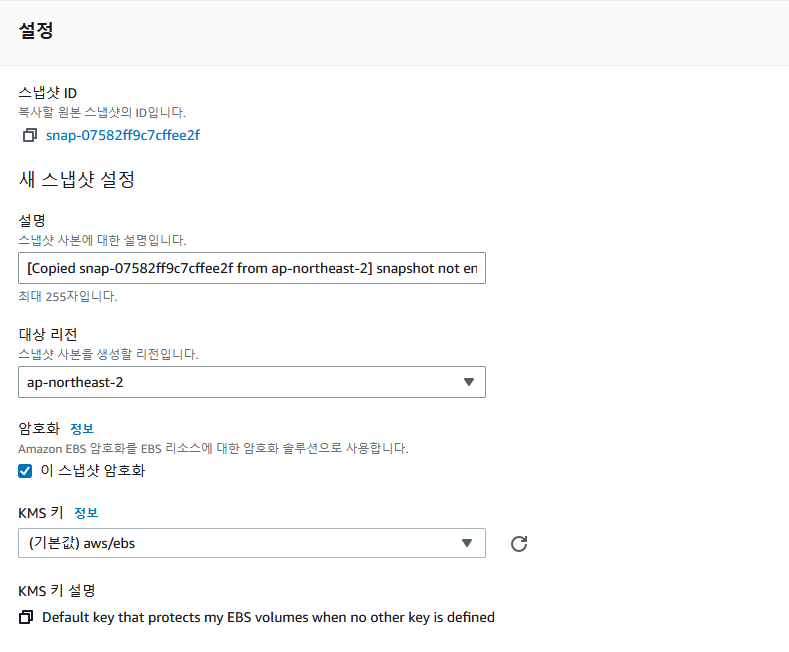
101. Route 53- 도메인 등록 실습
새 도메인 등록 - Amazon Route 53
등록자 연락처는 이메일의 지시 사항에 따라 이메일을 받았다는 사실을 확인해야 합니다. 그렇지 않으면 ICANN에서 요구할 경우 도메인 이름이 일시 중지해야 합니다. 도메인이 일시 중지되면 인
docs.aws.amazon.com
102. Route 53 - 첫번째 기록 생성
도메인에 레코드를 추가해본다.
.xxx.test.com
이런식으로 하고 ip 주소는 123.123.123.123 으로 연결한다. 레코드 타입은 A
xxx.test.com 을 입력하면 페이지가 안나온다
123.123.123.123. 은 없기 때문?
하지만 cloudshell에서 nslookup으로 xxx.test.com
을 검색하면 ip주소가 123.123.123.123 으로 연결되는 것을 확인할 수 있다.
또는 dig 명령어로 많은 정보를 확인할 수 있다.
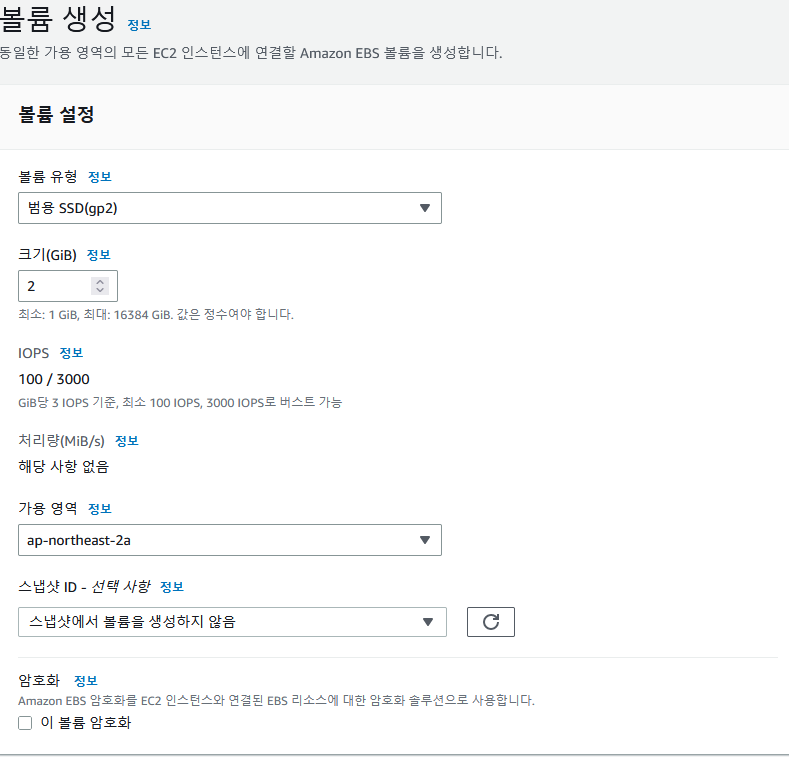
103. Route 53 -EC2 설정
EC2 생성
각 다른 리전에 인스턴스 3개를 만들고 애플리케이션 로드 밸런서를 하나 만든다 .
ssh, http 트패릭 허용 (로드밸런서는 다른 리전의 인스턴스도 연결해주는 구나)
#!/bin/bash
yum update -y
yum install -y httpd
systemctl start httpd
systemctl enable httpd
EC2_AVAIL_ZONE=$(curl -s http://169.254.169.254/latest/meta-data/placement/availability-zone)
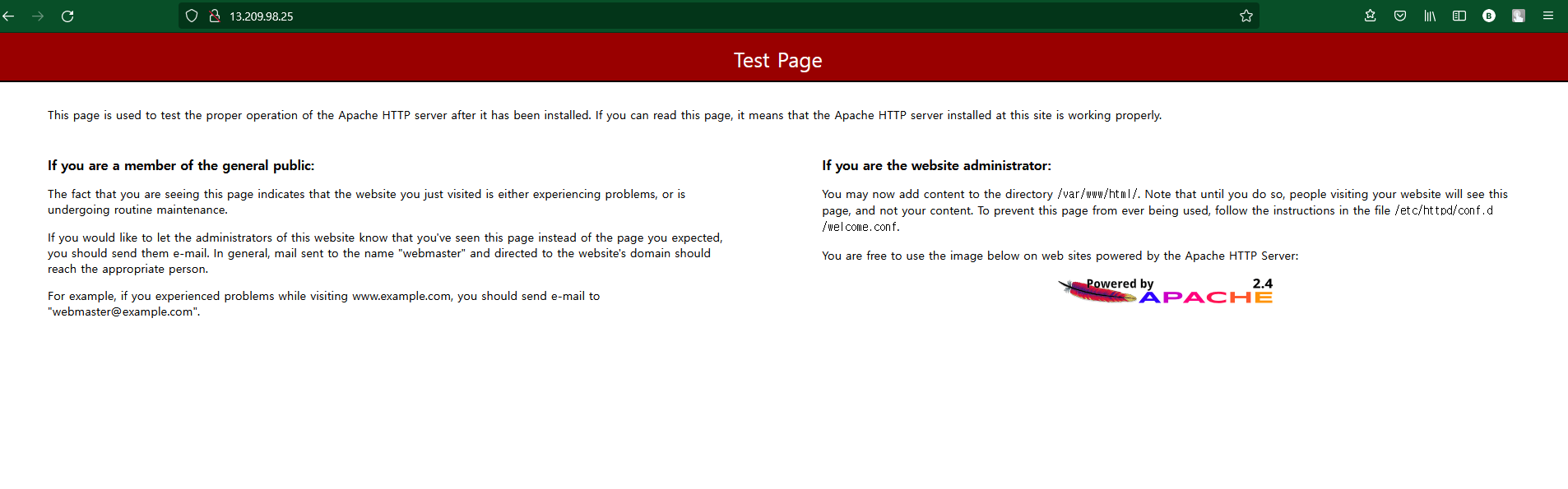
echo "<h1>Hello World from $(hostname -f) in AZ $EC2_AVAIL_ZONE </h1>" > /var/www/html/index.html사용자 데이터 스크립트
$EC2_AVAIL_ZONE
명령을 통해 가용영역 정보도 띄운다 .
로드 밸런서 생성
ALB 를 생성한다.
대상 그룹을 생성한다.
ALB 정보에서 DNS 이름을 복사해서 프로비저닝 됐는지 확인
ALB에서 인스턴스 하나늘 가리키게 된다.
104. Route 53 - TTL

클라이언트가 DNS route 53과 웹 서버에 접속한다고 가능하자.
myapp.example.com 에서 DNS 요청을 보내면 DNS 로부터 회신을 받는데
A 레코드와 IP 주소 그리고 TTL 을 받는다.
TTL이 300초라면 클라이언트가 요청 결과를 300초 동안 캐싱하게 한다.
300초 안에 똑같은 검색을 하면 route 53에 쿼리할 필요없이 바로 웹서버에 접속한다.
TTL 을 설정함으로써 DNS 서버의 부담을 줄일 수 있다.
High TTL - ex 24 hour
길게 잡으면 트래픽량을 줄일 수 있다.
너무 길면 오래된 데이터를 갖게된다.
Low TTL - ex 60sec
트래픽이 증가한다. -> 고비용
레코드를 최신으로 유지할 수 있다.
레코드를 변경하기 쉽다.
TTL을 콘솔에서 다루는 법
레코드를 생성한다.
TTL을 설정 120 초
EC2 - 1 에 연결하고
등록한 도메인으로 접속한다.
그리고 cloudshell에서 ns lookup 과 dig 명령어로 TTL 이 뜨는 것을 볼 수 있다.
클라이언트에서 접속했기 때문에 115초~ 이런식으로 TTL 이 뜬다
그 사이에 레코드에서 다른 EC2 -2 에 연결한다.
120초 내라면 변경된 EC2 -2 에 연결되는 것이 아니라 캐싱 시간 때문에 EC2 -1 으로 연결된다 .
105. Route 53 CNAME vs Alias
CNAME vs Alias
AWS Resources ( Load Balancer , CloudFront) 등 호스트 이름이 노출된다.
보유한 도메인에 호스트 이름을 매핑하려고 할 것이다.
myapp.mydomain.com 에 로드 밸런서를 매핑하는 경우 두가지 옵션이 있다.
CNAME
호스트 네임을 다른 호스트 네임으로 전환한다.
app.mydomain.com -> blabla.anything.com
루트 도메인 이름이 아닌 경우에만 가능하다.
Only for Non Root Domain
그냥 mydomain.com을 anything.com 으로 연결 시키는 것은 불가능하다.
Alias
호스트 네임을 특정 AWS 리소스로 향하도록 할 수 있다.
app.mydomain.com 이 blabla.amazonaws.com 을 향할 수 있게한다.
별칭 레코드는 루트 및 비루트 도메인에서 모두 작동한다.
works for Root Domain and Non Root Domain
비용은 무료이다.
자체적으로 상태 확인이 가능하다. native health check
Route 53 - Alias Records
호스트 네임을 aws 리소스만 향하게 한다.
DNS의 확장 기능으로 시중의 모든 DNS 에서 사용가능하다.
리소스 IP의 변화를 자동적으로 인식한다.
ALB에서 IP 가 바뀌면 별칭 레코드는 이걸 바롤 인식한다.

CNAME 과 달리 별칭 레코드는 ZONE APEX 라는 DNS 네임스페이스의 상위노드로 사용될 수 있다.
example.com 에도 별칭레코드를 사용할 수 있다.
AWS리소스를 위한 별칭 레코드의 타입은 항상 A 또는 AAAA이다.
리소스는 IPv4 또느 IPv6이다.
별칭 레코드는 TTL 설정 불가
Route 53 - Alias Records Targets

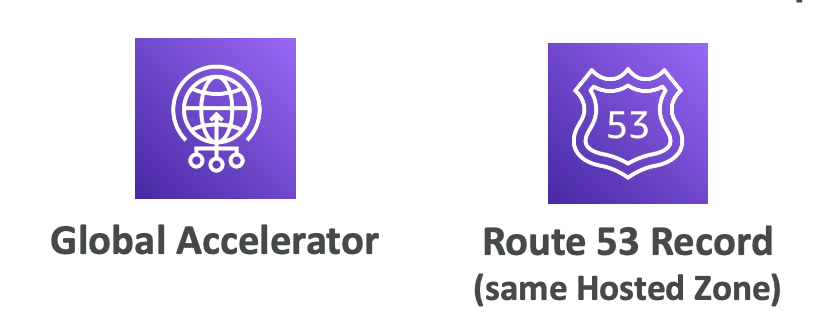
ELB, CloudFront, API Gateway, Elastic Beanstalk, S3 Websites, VPC Interface Endpoints
Global Accelerator , Route 53 Record
등 별칭 레코드의 대상으로 지정할 수 있다.
단 EC2의 DNS 이름에 대해서는 별칭 레코드를 설정할 수 없다.
106. 라우팅 정책 - 단순
Route 53 - Routing Policies
라우팅 정책은 route 53이 dns 쿼리에 응답하는 것을 돕는다.
라우팅
- 여기서 라우팅은 로드밸런서가 트래픽을 백엔드 EC2 인스턴스로 라우팅하는 것과 다르다.
- DNS does not route any traffic, it noly responds to the DNS queries
- DNS는 트래픽을 라우팅하지 않는다. 트래픽은 dns를 통과하지 않는다. DNS는 쿼리에만 응답하게 된다.
DNS는 호스트 이름들을 클라이언트가 실제 사용 가능한 엔드포인트로 변환하는 것을 돕느다.
Route 53 라우팅 정책
단순, 가중치 기반, 장애 조치 지연 시간 기반, 지리적, 다중 값 응답, 지리 근접
Routing Policies - Simple
기존에 우리가 사용해 왔던 방식이다.
일반적으로 트래픽을 단일 리소스로 보내는 방식이다.

클라이언트가 foo.example.com 으로 가고자 한다면 Route 53 이 iP 주소를 알려준다. a 레코드 주소
동일한 레코드에 여러 개의 값을 지정하는 것도 가능하다.
이렇게 DNS 에 의해 다중 값을 받는 경우에는 클라이언트 쪽에서 그중 하나를 고른다 .
alias 기능이 켜져있으면 오직 하나의 aws 리소스에만 접근할 수 있다.
헬스 체크 기능을 사용할 수 없다.
107. 라우팅 정책 - 가중치
Routing Policies - Weighted
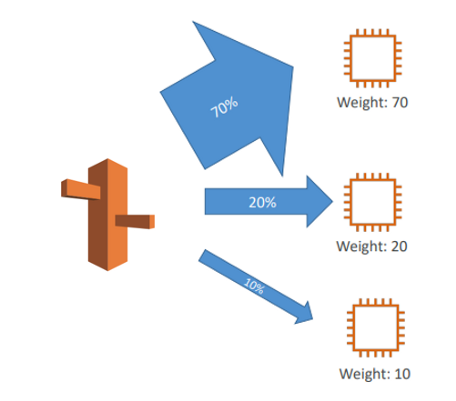
가중치 기반 라우팅 정책
정책을 사용하면, 가중치를 활용해 요청의 일부 비율을 특정 리소스로 보내는 식의 제어가 가능하다.
Control the % of the requests that go to each specific resource
Route 53 이 있고 EC2 인스턴스가 세 개 있는데 70, 20 , 10 의 각각 다른 가중치를 할당 받는다.
Amazon Route 53 에서 오는 DNS 응답의 70% 가 첫 번째 EC2 로 리다이렉팅 된다는 것을 의미한다.
20 퍼센트는 두 번쨰로 , 10퍼센트는 세 번째 인스턴스로 간다.
한 DNS 이름 하에 있는 다른 레코들과 비교했을 떄 해당 레코드로 트래픽을 얼마나 보낼지를 나타내는 값이다.
상태확인과 관련 될 수 있다. ( can be associated with health checks )
사용처
서로 다른 지역들에 걸쳐 로드 밸런싱을 할때
적은 양의 트래픽을 보내 새 애플리케이션을 테스트하는 경우
가중치 0의 값을 보내게 되면 특정 리소스에 트래픽 보내기를 중단해 가중치를 바꿀 수 있다.
모든 가중치를 0으로 하면 모든 레코드에 동등하게 보내진다.
새로운 레코드를 만든다 .
가중치 정책
레코드 id로 식별하기
108. 라우팅 정책 - 대기 시간
Routing Policies - Latency- based
지연 시간 기반 라우팅 정책
지연 시간이 가장 짧은 ,즉 가장 가까운 리소스로 리다이렉팅을 하는 정책이다.
Redirect to the resource that has the least latency close to us
지연 시간에 민감한 웹사이트나 애플리케이션이 있는 경우에 아주 유용한 정책이다.
지연 시간은 유저가 레코드로 가장 가까운 식별된 AWS 리전에 연결하기까지 걸리는 시간을 기반으로 측정된다.
Latency is based on traffic between users and AWS Regions
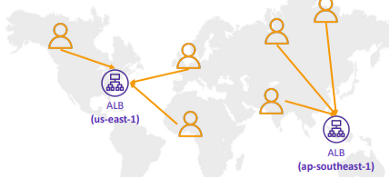
유저가 독일에 있고 미국에 있는 리소스의 지연시간이 가장 짧다면, 해당 유저는 미국 리전으로 리다이렉팅 될 것이다.
상태 확인과 연결이 가능하다.
정책을 레이턴시Latency로 지정한다.
인스턴스의 ip를 입력하고 리전 위치도 입력해야한다.
가장 가까운 인스턴스로만 연결된다.
109. Route 53 - 상태 확인
Route 53 - Health Checks
공용 리소스에 대한 상태를 확
인하는 방법이다.
지연 시간 기반 레코드로 연결되면 가장 가까운 리전의 ELB로만 연결될 것이다 .
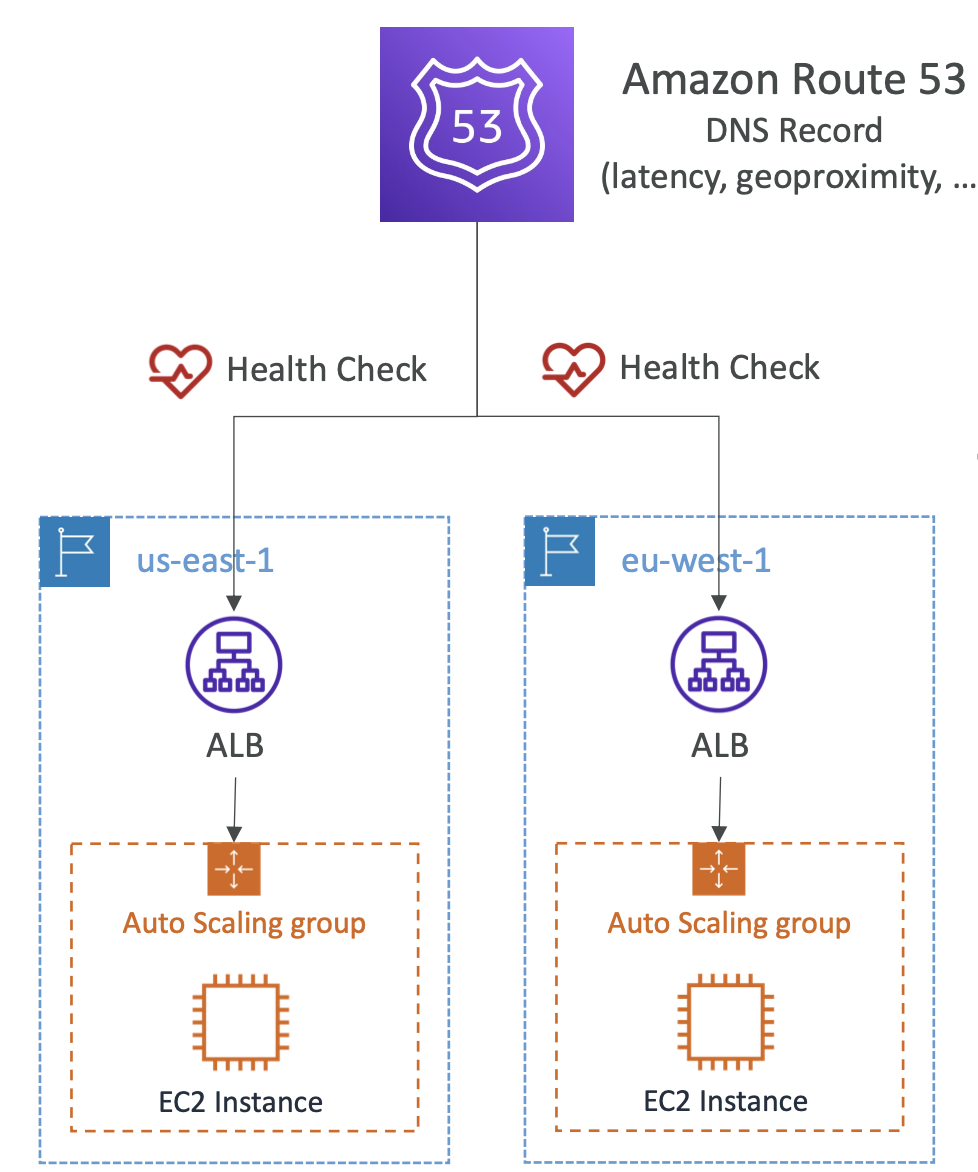
만약 ELB가 마비된다면 다른 리전은 ELB로 연결해야 할 것이다.
상태 체크를 통해 DNS 장애 조치를 자동화할 수 있다.
1. 엔드포인트에 대한 상태체크
( 애플리케이션, 서버, 다른 aws 리소스)
2. 다른 상태 확인을 모니터링하는 상태 확인도 있다.
(계산된 상태 체크 ) Calculated Health Checks
3.CloudWatch 를 통해 상태 확인
CloudWatch의 지표에서 확인 가능하다 .
Health Checks are intergrated with CW metrics
Health Checks - Monitor an Endpoint

15개의 글로벌 상태 확인이 엔드포인트의 상태를 확인하고 임계값을 정상 혹은 비정상으로 설정한다.
- 간격을 설정할 수 있다. 30~10초 (물론 10초 , 주기적으로 하면 비용이 더 든다.)
- 프로토콜 지원 :HTTP, HTTPS, TCP 를 지원한다.
- 18 % 이상의 상태 확인이 엔드 포인트를 정상이라고 판단하면 Route53도 이를 정상이라고 간주한다.
- 상태 확인에서 사용될 위치도 선택할 수 있다.
2xx, 3xxx 코드를 받아야만 통과가 된다.
텍스트 기반 응답일 경우 상태 확인은 응답의 처음 5120 바이트를 확인한다.
상태 확인의 작동이 가능하려면 상태 확인이 여러분의 애플리케이션 밸런서나 엔드 포인트에 접근이 가능해야한다.
따라서 Route53 의 상태 확인 IP 주소 범위에서 들어오는 모든 요청을 허용해야한다.
Calculated Health Checks

계산된 상태 확인으로 여러 개의 상태 확인 결과를 하나로 합쳐주는 기능이다.
Route 53 을 보면 EC2 인스턴스가 세 개 있고 상태 확인을 세 개 생성할 수 있다.
하위 상태를 바탕으로 상위 상태 확인을 정의할 수 있다.
상태 확인을 합치기 위한 조건은 OR, AND or NOT 이다
하위 상태 확인을 256개까지 모니터링할 수 있다.
상위 상태 확인이 통과하기 위해 몇 개의 상태를 통과해야 하는 지도 지정할 수 있다.
Usage:
상태 확인이 실패하는 일 없이 상위 상태 확인이 웹사이트를 관리 유지하도록 하는 경우
perform maintenance to your website without causing all health checks to fail
Health Checks - Private Hosted Zones

route 53의 상태 확인은 공용 웹에 있다. (VPC 외부에 있음)
개인 엔드 포인트에 접근하는 것은 불가능하다.
CloudWatch 지표를 만들어 CloudWatch 알람을 할당하는 식으로 문제를 해결할 수 있다.
개인 서브넷 안에 있는 EC2 인스턴스를 모니터링한다.
메트릭이 침해되는 경우 CloudWatch 알람을 생성하게 된다.
alarm 상태가 되면 상태 확인은 자동으로 비정상이 된다.
경보 상태가 되면 Health checks 가 통과하지 못하도록 하게 한다.
110. Route 53 - 상태 확인 실습
상태 확인 인스턴스 생성
엔드포인트 지정 - ec2 연결
상태 확인 관련 옵션 지정
( 상태 확인 3개 만든다. )
ec2 로 가서 보안 규칙을 일부러 변경한다.
상태확인에서 unhealthy로 변경된다.
Amazon Route 53 상태 확인 생성 및 DNS 장애 조치 구성 - Amazon Route 53
111. 라우팅 정책 - 장애 조치
Routing Policies - Failover ( Active-Passive)

route 53에서 주 인스턴스에 상태체크를 보냈는데 실패를 응답 받으면 보조 인스턴스로 연결함으로써 장애 조치를 한다.
보조 인스턴스에도 상태체크를 할 수 있지만 안할 수도 있다.
클라이언트가 접속하면 route 53는 보조 인스턴스로 응답을 한다.
장애 조치 정책을 설정하면 프라이머리, 세컨더리 레코드를 지정해야한다.
마찬가지로 보안그룹의 포트를 제거하여 접속 오류를 만든다.
장애가 생겼기 때문에 장애 조치로 연결한 세컨더리 레코드로 연결된다.
112. 라우팅 정책 - 지리적 위치
Routing Policies - Geolocation

지연 시간 기반 (latency-based) 정책과 다르다.
사용자의 실제 위치를 기반으로 한다.
사용자가 특정 대륙이나 국가 혹은 더 정확하게 미국의 경우에는 어떤 주에 있는지 지정하는 것이며 가장 정확한 위치가 선택되어 그 IP로 라우팅 되는 것이다.
일치하는 위치가 없는 경우에는 기본 레코드를 생성해야한다.
Should create a "Default" record ( in case there's no match on locaton)
Usage
콘텐츠 분산을 제한하고 로드 밸런싱 등을 실행하는 웹사이트 현지화가 있다.
독일 유저가 독일어 버전의 앱을 포함한 IP로 접속되로고 독일의 지리 레코드를 정의하고
프랑스의 경우 프랑스어 버전의 앱을 가진 IP로 가야한다.
그 외의 다른 곳은 앱에서 영어 버전이 포함된 기본 IP로 이동해야한다.
라우팅 정책 geolocation 으로 설정
타임아웃 오류가 뜬다면 보안그룹을 확인하자 .
vpn을 통해 검증하기
113. 라우팅 정책 - 지리적 근접성
Geoproximity Routing Policy
지리적 위치랑 차이점 주의하자.
사용자와 리소스의 지리적 위치를 기반으로 트래픽을 리소스로 라우팅하도록 한다.
편향값을 사용해 특정 위치를 기반으로 리소를 더 많은 트래픽을 이동하는 것이다.
지리적 위치를 변경하려면 편향값을 지정해야한다.
특정 리소스에 더 많은 트래픽을 보내려면 편향값을 증가시켜서 확장하면 된다.
To change the size of the geographic region, specify bias values:
- to expand (1 to 99) - more traffic to the resouce
- to shrink( -1 to -99) - less traffic to the resource
Resouces can be
- AWS resources (특정 리전)
- Non-AWS resources ( 특정 위도 , 경도를 지정하여 aws 가 위치를 파악하도록 해야한다)
편향 활용을 위해 고급 Route 53 트래픽 플로우를 사용한다.
you must use route 53 traffic flow (advanced) to use this feature
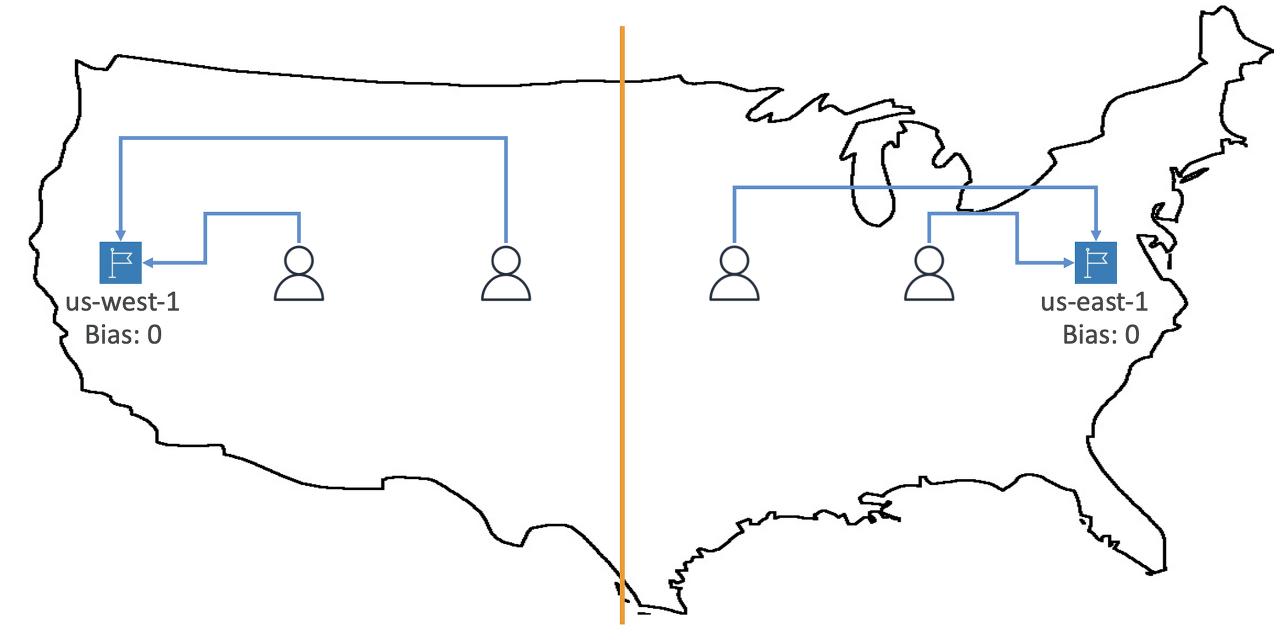

편향성이 0이면 유저는 가까운 리전으로 연결된다.
편향성을 지정하면 유저의 트래픽을 특정 리전으로 옮길 수 있다.
지리 근접 라우팅은 편향을 증가시켜
한 리전에서 다른 리전으로 트래픽을 보낼 때 유용한다.
114. 라우팅 정책 - 다중 값
Routing Policies - Multi-Value
다양한 리소스로 라우팅할때 사용된다.
Route 53 다중 값과 리소스를 반환한다.
상태 체크를 하는데 통과된 리소스만 반환한다.
return only values for healthy resources
각가의 다중 값 쿼리에 최대 8개의 정상 레코드가 반환된다.
up to 8 healyh recoreds are returned for each Multi-Value query
ELB와 유사해 보이지만 ELB를 대체할 수는 없다.
Multi-Value is not a substitute for having an ELB
단순 라우팅 정책은 상태 체크를 하지 않기 때문에 응답 받은 리소스 중에 비정상이 포함될 가능성이 있다.

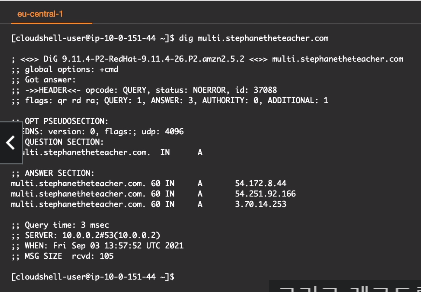
3개의 응답을 얻는다.
115. 타사 도메인 및 Route 53
Domain Registar vs. DNS Service
도메인 이름 레지스트라를 통해 원하는 도메인 이름을 구매할 수 있다.
매년 비용을 지불해야한다.
Route 53에서 도메인을 구매할 때는 Amazon 레지스트라를 이용했다.
GoDaddy에서 도메인을 구매하고 route53으로 관리 할 수도 있다.


Route 53에서 원하는 도메인의 공용 호스팅 영역을 생성하고 호스팅 영역 상세의 오른쪽 부분에서 이름 서버를 찾는다.
해당 이름 서버는 godaddy 에서 수정해야한다.
godaddy에서 사용하는 네임서버에 관한 쿼리에 응답하면 네임서버가 route 53의 네임서버를 가리키게 된다.
그러면 route 53의 콘솔에서 직접 전체 dns 레코드를 관리할 수 있다.
3rd Party Registrar with Amazon Route 53
1. 3파티에서 도메인을 구매하고 네임서버를 등록한다.
2. route 53에 호스팅 존을 생성한다.
3. 3파티 웹사이트에서 네임서버 레코드를 수정한다. route 53의 네임 서버를 사용하기위해!
도메인 레지스트라와 dns service는 다르다 .
그러나 대부분의 도메인 레지스트라는 dns 기능을 지원한다.
116. Route 53 - 섹션 정리
실습에 사용한 인스턴스 제거
도메인 제거
Route 53 퀴즈
1. 여러분은 Amazon Route 53 Registrar를 위해 mycoolcompany.com를 구매했으며, 이 도메인이 Elastic Load Balancer인 my-elb-1234567890.us-west-2.elb.amazonaws.com를 가리키게끔 하려 합니다. 이런 경우, 다음 중 어떤 Route 53 레코드 유형을 사용해야 할까요?

2.새로운 Elastic Beanstalk 환경을 배포한 상태에서, 5%의 프로덕션 트래픽을 이 새로운 환경으로 다이렉트하려 합니다. 이를 통해 CloudWatch 지표를 모니터링하여, 새로운 환경에 있는 버그를 제거할 수 있게 됩니다. 이런 작업을 위해서는 다음 중 어떤 Route 53 레코드 유형을 사용해야 할까요?

가중치 기반 라우팅 정책을 사용하면 가중치(예: 백분율)를 기반으로 트래픽의 일부를 리다이렉트할 수 있습니다. 트래픽의 일부를 애플리케이션의 새로운 버전으로 보내는 방식은 흔히 사용되는 방식입니다.
트래픽을 분산 시키는 것을 목적이라면 가중치 기반, 지리적 근접성을 라우팅 정책으로 한다.
3. Route 53 레코드의 myapp.mydomain.com 값이 새로운 Elastic Load Balancer를 가리키도록 업데이트를 했는데도 불구하고, 사용자들은 여전히 기존의 ELB로 리다이렉트 되고 있는 상태입니다. 이런 경우, 가능성이 있는 원인은 무엇일까요?

각 DNS 레코드는 클라이언트들이 이러한 값들을 캐시할 기간을 지정하고 DNS 요청으로 DNS 리졸버에 과부하를 일으키지 않도록 지시하는 TTL(타임 투 리브)을 갖습니다. TTL 값은 값을 캐시해야 하는 기간과 DNS 리졸버로 들어가야 하는 요청의 수 사이의 균형을 유지할 수 있도록 설정되어야 합니다.
4. 두 AWS 리전, us-west-1 및 eu-west-2에 호스팅 된 애플리케이션이 있습니다. 애플리케이션 서버의 사용자에 대한 응답 시간을 최소화하여, 사용자들에게 최상의 사용자 경험을 제공하려 합니다. 이 경우, 다음 중 어떤 Route 53 라우팅 정책을 사용해야 할까요?

지연 시간 라우팅 정책은 사용자와 AWS 리전 사이에서 발생하는 지연 시간을 평가하여 지연 시간(예: 응답 시간)을 최소화할 수 있는 DNS 응답을 수신할 수 있게 해줍니다.
5. 프랑스를 제외한 국가에 있는 사람들이 여러분의 웹사이트로 액세스해서는 안 된다는 법적 요구 사항이 있습니다. 이 경우, 다음 중 어떤 Route 53 라우팅 정책을 사용해야 할까요?

6. GoDaddy를 위해 도메인을 구매했으며, Route 53을 DNS 서비스 제공자로 사용하려 합니다. 이를 위해서는 어떤 작업을 수행해야 할까요?

공용 호스팅 영역은 인터넷을 통해 웹사이트로 요청을 보내는 사람들이 사용할 것을 전재하고 있습니다. 마지막으로, NS 레코드는 타사 Registrar에 업데이트되어야 합니다.
7. 다음 중 유효한 Route 53 상태 확인이 아닌 것을 고르세요.