2022.12.26 - [DevOps/aws] - AWS Cloud Practitioner Essentials | 모듈1: AMAZON WEB SERVICES 소개
2022.12.26 - [DevOps/aws] - AWS Cloud Practitioner Essentials | 모듈 2: 클라우드 컴퓨팅
2022.12.27 - [DevOps/aws] - AWS Cloud Practitioner Essentials | 모듈 3: 글로벌 인프라 및 안정성
모듈 4 소개
학습 목표
- 네트워킹의 기본 개념을 설명할 수 있습니다.
- 퍼블릭 네트워킹 리소스와 프라이빗 네트워킹 리소스의 차이점을 설명할 수 있습니다.
- 실제 시나리오를 사용하여 가상 프라이빗 게이트웨이를 설명할 수 있습니다.
- 실제 시나리오를 사용하여 Virtual Private Network(VPN)를 설명할 수 있습니다.
- AWS Direct Connect의 이점을 설명할 수 있습니다.
- 하이브리드 배포의 이점을 설명할 수 있습니다.
- IT 전략에서 사용되는 보안 계층을 설명할 수 있습니다.
- 고객이 AWS 글로벌 네트워크와 상호 작용하기 위해 사용하는 서비스를 설명할 수 있습니다.
vpc
사용자가 정의한 가상 네트워크에서 AWS 리소스를 실행할 수 있는 논리적으로 격리된 aws 클라우드 섹션을 프로비저닝 할 수 있다.
AWS 와의 연결
Amazon Virtual Private Cloud(Amazon VPC)
vpc는 본질적으로 aws에서의 사용자 고유 프라이빗 네트워크 입니다.
서브넷은 vpc 내의 ip 주소 모음으로 리소스를 그룹화 할 수 있게 도와준다 .
AWS 서비스를 사용하는 수백만 명의 고객을 상상해 보십시오. 또한 이들 고객이 생성한 Amazon EC2 인스턴스와 같은 수백만 개의 리소스를 상상해 보십시오. 이러한 모든 리소스에 경계가 없으면 네트워크 트래픽이 제한 없이 리소스 간에 흐를 수 있습니다.
AWS 리소스에 경계를 설정하는 데 사용할 수 있는 네트워킹 서비스가 Amazon Virtual Private Cloud(Amazon VPC)입니다.
=> VPC 로 네트워크 간 경계를 만든다.
Amazon VPC를 사용하여 AWS 클라우드의 격리된 섹션을 프로비저닝할 수 있습니다. 이 격리된 섹션에서는 사용자가 정의한 가상 네트워크에서 리소스를 시작할 수 있습니다. 한 Virtual Private Cloud(VPC) 내에서 여러 서브넷으로 리소스를 구성할 수 있습니다. 서브넷은 리소스(예: Amazon EC2 인스턴스)를 포함할 수 있는 VPC 섹션입니다.
인터넷 게이트웨이

인터넷의 퍼블릭 트래픽이 VPC에 액세스하도록 허용하려면 인터넷 게이트웨이를 VPC에 연결합니다.
=> 인터넷 게이트웨이를 통해 퍼블릭 트래픽이 vpc에 액세스 할 수 있다.
인터넷 게이트웨이는 VPC와 인터넷 간의 연결입니다. 인터넷 게이트웨이는 고객이 커피숍에 들어가기 위해 사용하는 출입문과 비슷한 것으로 생각할 수 있습니다. 인터넷 게이트웨이가 없으면 아무도 VPC 내의 리소스에 액세스할 수 없습니다.
가상 프라이빗 게이트웨이

VPC 내의 비공개 리소스에 액세스하려면 가상 프라이빗 게이트웨이를 사용할 수 있습니다.
다음은 가상 프라이빗 게이트웨이 작동 방식의 예입니다. 인터넷은 집과 커피숍 사이의 도로로 생각할 수 있습니다. 이 도로를 보디가드와 함께 지나간다고 가정해 보십시오. 다른 고객과 동일한 도로를 사용하고 있지만 추가 보호 계층이 있습니다.
보디가드는 주변의 다른 모든 요청으로부터 인터넷 트래픽을 암호화(또는 보호)하는 가상 프라이빗 네트워크(VPN) 연결과 같습니다.
가상 프라이빗 게이트웨이는 보호된 인터넷 트래픽이 VPC로 들어오도록 허용하는 구성 요소입니다. 커피숍까지 가는 도로에는 추가적인 보호 기능이 있지만 다른 고객과 동일한 도로를 사용하고 있기 때문에 교통 체증이 발생할 수 있습니다.
가상 프라이빗 게이트웨이를 사용하면 VPC와 프라이빗 네트워크(예: 온프레미스 데이터 센터 또는 회사 내부 네트워크) 간에 가상 프라이빗 네트워크(VPN) 연결을 설정할 수 있습니다. 가상 프라이빗 게이트웨이는 승인된 네트워크에서 나오는 트래픽만 VPC로 들어가도록 허용합니다.
=> 가상 프라이빗 게이트웨이를 통해 특정한 네트워크(VPN)로부터의 접속만 허용할 수 있다.
AWS Direct Connect

AWS Direct Connect는 데이터 센터와 VPC 간에 비공개 전용 연결을 설정하는 서비스입니다.
커피숍과 직접 연결되는 복도가 있는 아파트 건물이 있다고 가정해 보겠습니다. 아파트 입주자만 이 복도를 사용할 수 있습니다.
이 사설 복도는 AWS Direct Connect와 동일한 유형의 전용 연결을 제공합니다. 입주민은 다른 고객도 함께 사용하는 공공 도로를 거칠 필요 없이 커피숍에 들어갈 수 있습니다.
AWS Direct Connect가 제공하는 비공개 연결은 네트워크 비용을 절감하고 네트워크를 통과할 수 있는 대역폭을 늘리는 데 도움이 됩니다.
=> AWS Direct connect 를 통해 데이터 센터와 vpc 사이의 전용 연결을 설정할 수 있다.
서브넷 및 네트워크 액세스 제어 목록
vpc 에 들어가기 위해서 게이트웨이를 걸쳐야한다.
vpc에서 서브넷을 사용해야하는 유일한 기술적인 이유는 게이트웨이에 대한 액세스 관리를 위해서이다.
인터넷 게이트 웨이 -> acl( 서브넷 경계) -> 보안그룹 (인스턴스 단에서 )
보안그룹
인바운드는 체크하지만
아웃바운드는 들어온 패킷에 대해서는 자유롭게 나가게 해준다.
보안그룹은 상태를 저장한다.
acl은 stateless 하다.( 상태 비저장)
들어오고 나갈때 다 체크한다.

VPC 내에서 서브넷의 역할에 대해 자세히 알아보기 위해 다음과 같은 커피숍 예를 살펴보겠습니다.
먼저, 고객이 계산원에게 음료를 주문합니다. 그러면 계산원이 바리스타에게 주문을 전달합니다. 이 프로세스를 통해 더 많은 고객이 들어오더라도 계속 원활하게 주문을 받을 수 있습니다.
일부 고객이 계산원을 건너 뛰고 바리스타에게 직접 주문하려 한다고 가정해 보십시오. 그러면 주문 흐름이 중단되고 고객이 커피숍의 제한 구역에 접근하게 됩니다.
=> 고객이 바리스타에게 바로 접근하는 경우를 막아야한다.

이는 AWS 네트워킹 서비스를 사용하여 리소스를 격리하고 네트워크 트래픽의 흐름을 정확히 결정하는 것과 비슷합니다.
커피숍의 카운터 영역을 VPC로 생각할 수 있습니다. 카운터 영역은 계산원의 워크스테이션과 바리스타의 워크스테이션을 위해 두 개의 영역으로 나뉩니다. VPC에서 서브넷은 리소스를 그룹화하는 데 사용되는 별개의 영역입니다.
=> vpc 내를 서브넷 으로 그룹화 한다.
서브넷

서브넷은 보안 또는 운영 요구 사항에 따라 리소스를 그룹화할 수 있는 VPC 내의 한 섹션입니다. 서브넷은 퍼블릭 또는 프라이빗일 수 있습니다.
퍼블릭 서브넷에는 온라인 상점의 웹 사이트와 같이 누구나 액세스할 수 있어야 하는 리소스가 포함됩니다.
프라이빗 서브넷에는 고객의 개인 정보 및 주문 내역이 포함된 데이터베이스와 같이 프라이빗 네트워크를 통해서만 액세스할 수 있는 리소스가 포함됩니다.
VPC 내에서 서브넷은 서로 통신할 수 있습니다. 예를 들어 퍼블릭 서브넷에 있는 Amazon EC2 인스턴스가 프라이빗 서브넷에 있는 데이터베이스와 통신하는 애플리케이션이 있을 수 있습니다.
=> 퍼블릭 서브넷과 프라이빗 서브넷으로 나뉜다.
VPC의 네트워크 트래픽
고객이 AWS 클라우드에서 호스팅되는 애플리케이션에 데이터를 요청하면 이 요청은 패킷으로 전송됩니다. 패킷은 인터넷이나 네트워크를 통해 전송되는 데이터의 단위입니다.
=> 패킷 단위로 전송된다.
패킷은 인터넷 게이트웨이를 통해 VPC로 들어갑니다. 패킷이 서브넷으로 들어가거나 서브넷에서 나오려면 먼저 권한을 확인해야 합니다. 이러한 사용 권한은 패킷을 보낸 사람과 패킷이 서브넷의 리소스와 통신하려는 방법을 나타냅니다.
=> 패킷은 인터넷 게이트웨이를 거쳐 vpc로 진입한다.
서브넷의 패킷 권한을 확인하는 VPC 구성 요소는 네트워크 ACL(액세스 제어 목록)입니다.
네트워크 ACL(액세스 제어 목록)
네트워크 ACL(액세스 제어 목록)은 서브넷 수준에서 인바운드 및 아웃바운드 트래픽을 제어하는 가상 방화벽입니다.
예를 들어 이제 커피숍이 아닌 공항에 있다고 상상해 보십시오. 공항에서 여행자들이 입국 절차를 밟고 있습니다. 이러한 여행자를 패킷으로 생각할 수 있고 출입국 심사 직원을 네트워크 ACL로 생각할 수 있습니다. 출입국 심사 직원은 여행자가 출입국할 때 여행자의 신원 정보를 확인합니다. 여행자가 승인 목록에 있으면 통과할 수 있습니다. 그러나 여행자가 승인 목록에 없거나 금지 목록에 명시된 경우에는 입국할 수 없습니다.
각 AWS 계정에는 기본 네트워크 ACL이 포함됩니다. VPC를 구성할 때 계정의 기본 네트워크 ACL을 사용하거나 사용자 지정 네트워크 ACL을 생성할 수 있습니다.
=> 서브넷 단에 진입할 때 네트워크 ACL을 거친다.
계정의 기본 네트워크 ACL은 기본적으로 모든 인바운드 및 아웃바운드 트래픽을 허용하지만 사용자가 자체 규칙을 추가하여 수정할 수 있습니다. 사용자 지정 네트워크 ACL은 사용자가 허용할 트래픽을 지정하는 규칙을 추가할 때까지 모든 인바운드 및 아웃바운드 트래픽을 거부합니다. 또한 모든 네트워크 ACL에는 명시적 거부 규칙이 있습니다. 이 규칙은 패킷이 목록의 다른 모든 규칙과 일치하지 않으면 해당 패킷이 거부되도록 합니다.
상태 비저장 패킷 필터링
네트워크 ACL은 상태 비저장 패킷 필터링을 수행합니다. 즉, 아무것도 기억하지 않고 각 방향(인바운드 및 아웃바운드)으로 서브넷 경계를 통과하는 패킷만 확인합니다.
앞서 예로 든 다른 국가에 입국하려는 여행자를 상기해 보십시오. 이는 Amazon EC2 인스턴스에서 인터넷으로 요청을 전송하는 것과 비슷합니다.
해당 요청에 대한 패킷 응답이 서브넷으로 반환될 때 네트워크 ACL은 이전 요청을 기억하지 못합니다. 네트워크 ACL은 규칙 목록에 따라 패킷 응답을 확인하여 허용 또는 거부 여부를 결정합니다.
=> acl은 상태를 저장하지 않기 때문에 패킷이 전송될 때마다 체크한다.

패킷이 서브넷에 들어간 후에는 서브넷 내의 리소스(예: Amazon EC2 인스턴스)에 대한 권한이 평가되어야 합니다.
패킷에서 Amazon EC2 인스턴스에 대한 권한을 확인하는 VPC 구성 요소는 보안 그룹입니다.
보안 그룹
보안 그룹은 Amazon EC2 인스턴스에 대한 인바운드 및 아웃바운드 트래픽을 제어하는 가상 방화벽입니다.

기본적으로 보안 그룹은 모든 인바운드 트래픽을 거부하고 모든 아웃바운드 트래픽을 허용합니다. 사용자 지정 규칙을 추가하여 허용 또는 거부할 트래픽을 구성할 수 있습니다.
=> 상태 저장, 인바운드로 인스턴스를 통과한 경우 나갈때 모든 아웃바운드 트래픽을 허용한다.
예를 들어 로비에서 방문객을 안내하는 경비원이 있는 아파트 건물을 생각해 보십시오. 방문객을 패킷으로 생각할 수 있으며 경비원을 보안 그룹으로 생각할 수 있습니다. 방문객이 도착하면 경비원은 방문객 목록을 보고 해당 방문객이 건물 안으로 들어갈 수 있는지 확인합니다. 그러나 방문객이 건물에서 나갈 때는 경비원이 목록을 다시 확인하지 않습니다.
서브넷 내에 여러 Amazon EC2 인스턴스가 있는 경우 동일한 보안 그룹에 연결하거나 각 인스턴스마다 서로 다른 보안 그룹을 사용할 수 있습니다.
상태 저장 패킷 필터링
보안 그룹은 상태 저장 패킷 필터링을 수행합니다. 즉, 들어오는 패킷에 대한 이전 결정을 기억합니다.
Amazon EC2 인스턴스에서 인터넷으로 요청을 전송하는 것과 동일한 예를 생각해 보십시오.
해당 요청에 대한 패킷 응답이 인스턴스로 반환될 때 보안 그룹이 이전 요청을 기억합니다. 보안 그룹은 인바운드 보안 그룹 규칙에 관계없이 응답이 진행하도록 허용합니다.
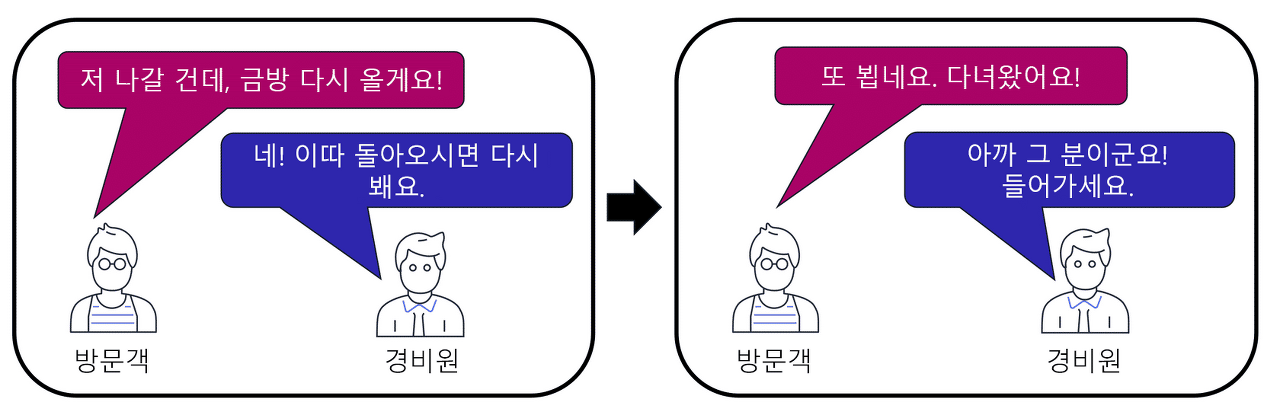
네트워크 ACL과 보안 그룹을 모두 사용하면 VPC에서 트래픽에 대한 사용자 지정 규칙을 구성할 수 있습니다. 계속해서 AWS 보안 및 네트워킹을 더 자세히 알아보려면 네트워크 ACL과 보안 그룹 간의 차이점을 이해해야 합니다.

인터넷 게이트웨이 -> acl -> sg 순으로 점검


글로벌 네트워킹
사용자는 어떻게 aws 인프라와 상호 작요할까?
dns는 웹사이트 네임을 인터넷 프로토콜로 번역한다.
cdn: 지리적 위치를 기반으로 사용자에게 엣지 콘텐츠를 제공하는 네트워크
Domain Name System(DNS)
AnyCompany가 AWS 클라우드에서 웹 사이트를 호스팅한다고 가정해 보겠습니다. 고객이 브라우저에 웹 주소를 입력하면 이 웹 사이트에 액세스 할 수 있습니다. 이것이 가능한 이유는 Domain Name System(DNS) 확인 때문입니다. DNS 확인에는 DNS 서버와 웹 서버 간 통신이 포함됩니다.
DNS를 인터넷의 전화번호부라고 생각할 수 있습니다. DNS 확인은 도메인 이름을 IP 주소로 변환하는 프로세스입니다.

예를 들어 AnyCompany의 웹 사이트를 방문한다고 가정해 보겠습니다.
1. 브라우저에 도메인 이름을 입력하면 이 요청이 DNS 서버로 전송됩니다.
2. DNS 서버는 웹 서버에 AnyCompany 웹 사이트에 해당하는 IP 주소를 요청합니다.
3.웹 서버는 AnyCompany 웹 사이트의 IP 주소인 192.0.2.0을 제공하여 응답합니다.
Amazon Route 53
Amazon Route 53는 DNS 웹 서비스입니다. 이 서비스는 개발자와 비즈니스가 최종 사용자를 AWS에서 호스팅되는 인터넷 애플리케이션으로 라우팅할 수 있는 안정적인 방법을 제공합니다.
Amazon Route 53는 사용자 요청을 AWS에서 실행되는 인프라(예: Amazon EC2 인스턴스 및 로드 밸런서)에 연결합니다. 또한 사용자를 AWS 외부의 인프라로 라우팅할 수 있습니다.
Route 53의 또 다른 기능에는 도메인 이름의 DNS 레코드를 관리하는 기능도 있습니다. Route 53에 직접 새 도메인 이름을 등록할 수 있습니다. 다른 도메인 등록 대행자가 관리하는 기존 도메인 이름의 DNS 레코드를 전송할 수도 있습니다. 그러면 단일 위치에서 모든 도메인 이름을 관리할 수 있습니다.
이전 모듈에서는 콘텐츠 전송 서비스인 Amazon CloudFront에 대해 알아보았습니다. 다음 예에서는 Amazon Route 53와 Amazon CloudFront가 함께 작동하여 고객에게 콘텐츠를 전송하는 방식을 설명합니다.
예: Amazon Route 53 및 Amazon CloudFront가 콘텐츠를 전송하는 방식

AnyCompany의 애플리케이션이 여러 Amazon EC2 인스턴스에서 실행 중이라고 가정하겠습니다. 이러한 인스턴스는 Application Load Balancer에 연결되는 Auto Scaling 그룹에 포함되어 있습니다.
1. 고객이 AnyCompany의 웹 사이트로 이동하여 애플리케이션에서 데이터를 요청합니다.
2. Amazon Route 53는 DNS 확인을 사용하여 AnyCompany.com의 IP 주소인 192.0.2.0을 식별합니다. 이 정보는 고객에게 다시 전송됩니다.
3. 고객의 요청은 Amazon CloudFront를 통해 가장 가까운 엣지 로케이션으로 전송됩니다.
4. Amazon CloudFront는 수신 패킷을 Amazon EC2 인스턴스로 전송하는 Application Load Balancer에 연결됩니다.

모듈 4 퀴즈
회사에 Amazon EC2 인스턴스를 사용하여 고객 대상 웹 사이트를 실행하고 Amazon RDS 데이터베이스 인스턴스를 사용하여 고객의 개인 정보를 저장하는 애플리케이션이 있습니다. 모범 사례에 따르면 개발자는 VPC를 어떻게 구성해야 합니까?

다음 중 회사의 데이터 센터와 AWS 간에 비공개 전용 연결을 설정하는 데 사용할 수 있는 구성 요소는 무엇입니까?

다음 중 보안 그룹을 가장 잘 설명한 것은 무엇입니까?

다음 중 VPC를 인터넷에 연결하는 데 사용되는 구성 요소는 무엇입니까?

다음 중 도메인 이름의 DNS 레코드를 관리하는 데 사용되는 서비스는 무엇입니까?

'aws' 카테고리의 다른 글
| AWS Cloud Practitioner Essentials | 모듈 6: 보안 (0) | 2022.12.29 |
|---|---|
| AWS Cloud Practitioner Essentials | 모듈 5: 스토리지 및 데이터베이스 (0) | 2022.12.28 |
| AWS Cloud Practitioner Essentials | 모듈 3: 글로벌 인프라 및 안정성 (0) | 2022.12.27 |
| AWS Cloud Practitioner Essentials | 모듈 2: 클라우드 컴퓨팅 (0) | 2022.12.26 |
| AWS Cloud Practitioner Essentials | 모듈1: AMAZON WEB SERVICES 소개 (0) | 2022.12.26 |